Meta 发布其最新款的开源模型:Llama 4 ,Llama 4 系列首批发布了两个可用模型:Llama 4 Scout 和 Llama 4 Maverick。并预告了一个仍在训练中的超大模型。
Llama 4 系列是 Meta 首次采用以下两种关键架构的模型系列:
- 专家混合架构(Mixture-of-Experts, MoE)
- 多模态能力(multi-modality)
为何这很重要?
- MoE 架构:将大模型划分为多个专门的“专家”,每个专注于特定任务。
- 针对每个输入,仅激活其中一小部分专家,从而在保持高性能的同时减少计算开销。
- 同时,Llama 4 是首个原生多模态的 Llama 模型系列。
Llama 4 模型通过“早期融合”技术整合文本、图像与视频:
与以往模型不同,Llama 4 从一开始就设计为原生支持文本、图像和视频的统一模型,采用所谓的“early fusion”方法。在训练阶段就将文本与视觉 token 融入统一模型骨干结构,而不是后期补丁式添加。
这一设计使得 Llama 4 系列(包括 Scout、Maverick 和预览中的 Behemoth)能有效处理并推理多种模态信息。
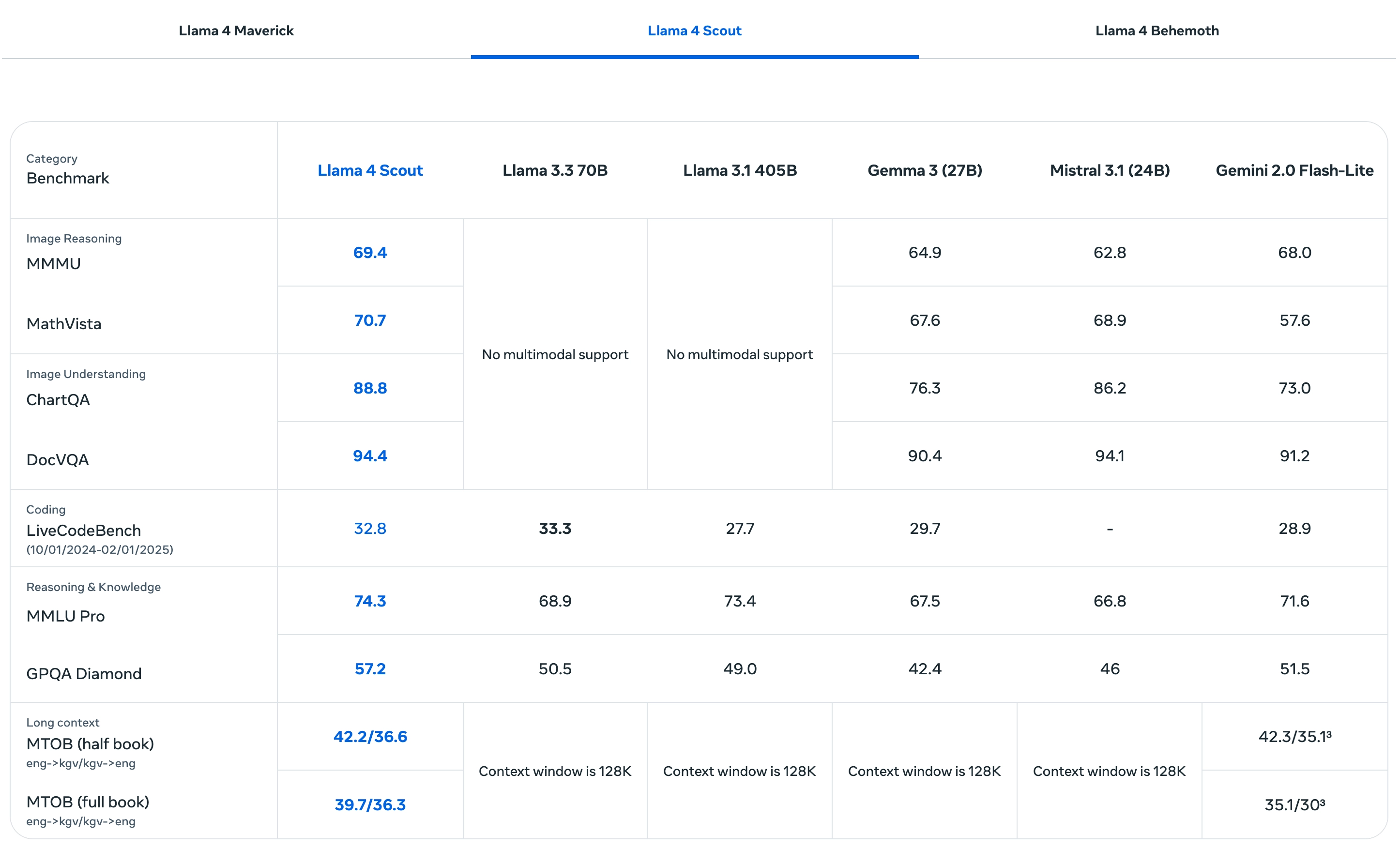
Llama 4 Scout:
- 是该系列中体量最小的模型,(17B 激活参数 / 109B 总参数)仅使用 17B 活跃参数(总参数为 109B),由 16 个专家构成。
- 支持超长输入上下文(最多 1000 万 tokens)。
- 通过“中期训练”(mid-training)和新型数据集提升模型质量。
- 能够部署在单张 NVIDIA H100 GPU 上。
- 拥有 业界领先的 1000 万 token 上下文窗口,非常适合多文档摘要与大型代码库推理。
在基准测试中优于同等规模模型,如 Gemini 2.0 Flash-Lite 和 Mistral 3.1。

Llama 4 Maverick:
上下文窗口为 100 万 token
(17B 激活参数 / 400B 总参数)同样使用 17B 活跃参数,但拥有多达 128 个专家,总参数量为 400B,远超 Scout。
面向通用 AI 助手与聊天应用。
相较 Scout,其最大优势是卓越的性价比,在推理、编程和图像任务方面表现行业领先。
在图像和文本理解方面表现业界领先,适合图像理解与创意写作。

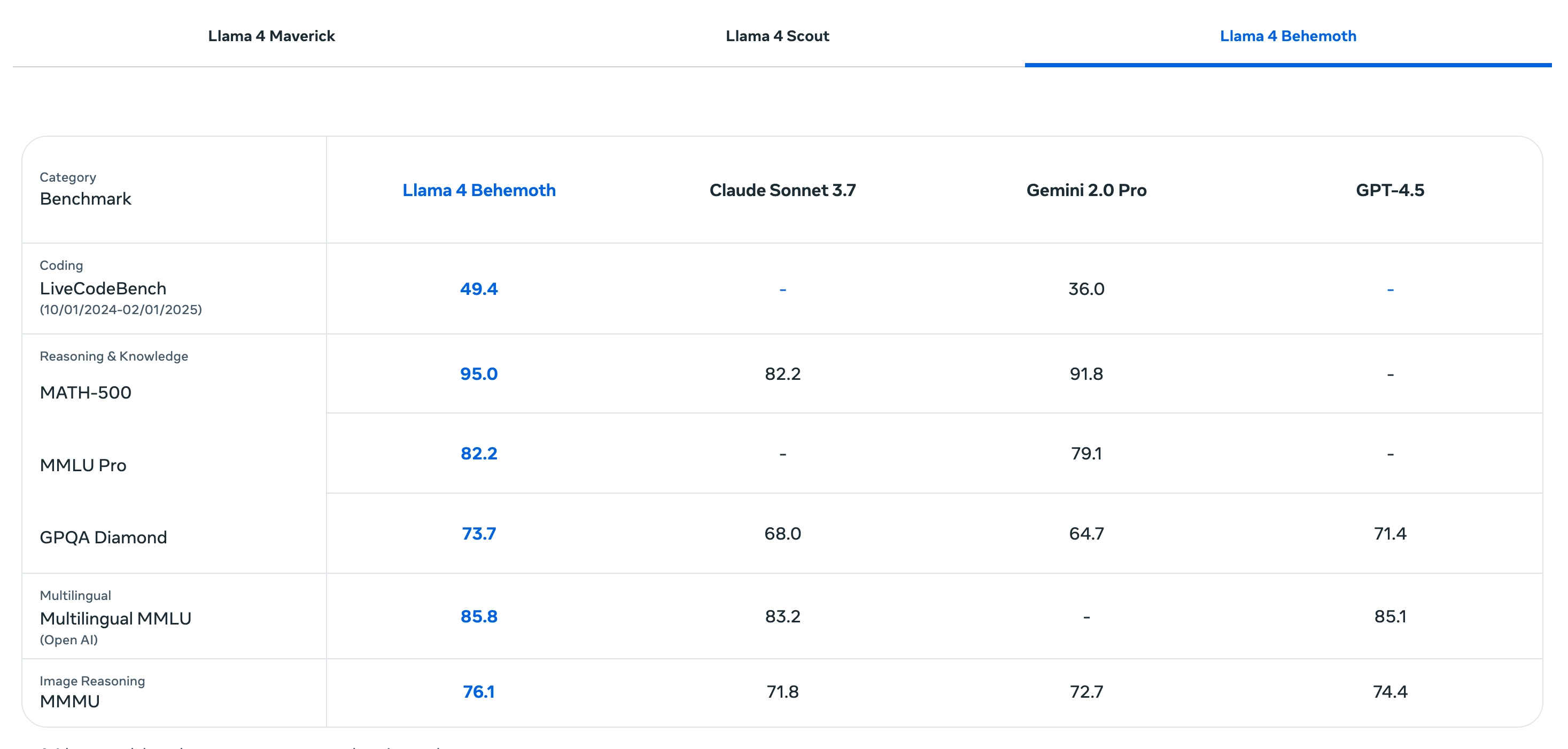
Llama 4 Behemoth(尚未发布):
- 是 Meta 有史以来最大的模型,这是 Llama 4 系列的“教师模型”(还在训练中)
用于蒸馏出 Scout 与 Maverick,具备更强通用能力
已知规格如下:
- 288B 活跃参数,16 个专家,总参数接近 2 万亿。
- 使用超过 30 万亿 tokens 进行训练(包含文本、图像与视频),数据量是 Llama 3 的两倍。
- 在 STEM 基准测试(如 MATH-500)中表现超过 GPT-4.5 与 Claude Sonnet 3.7。
- 虽未发布,但它标志着 Meta 正在向更复杂、专业化的多模态 AI 系统迈进。
Llama 4 是多模态 AI 能力的一次飞跃:
无论你是开发文本理解、视觉推理还是长文本处理类应用,Llama 4 都提供了强大支持。
Meta 还将在 4 月 29 日 LlamaCon 大会上公布更多关于 Llama 生态的未来计划与多模态创新的内容。
Llama 4 的主要特点
多模态能力
Llama 4 是 Meta 首个原生多模态模型,通过“早期融合”(early fusion)技术,将文本和视觉数据直接整合到模型主干中,而非后期附加。这种方法使其能够处理文本、图像、视频等多类型输入,并生成文本输出。训练数据包括超过 30 万亿个 token,涵盖大量未标记的文本、图像和视频数据,是 Llama 3 训练数据的两倍多。原生多模态支持(文字+图像):
- 可同时理解文本和图片,进行图文推理、问答、识别、描述等任务。
“Image Grounding”
- “Grounding” 指的是:将模型生成的语言输出建立在视觉实物或区域的基础上,使回答与图像中实际内容有明确联系。
- → Llama 4 在图像锚定方面的能力属于行业顶尖水平。
- → 模型能够理解用户的文字提示,并与图像中的相关视觉元素(概念)进行对应。
✅ 举例:如果你问“这张图中谁在微笑?”,模型知道你指的是“图中人物的表情”。 - → 模型的回答不只是泛泛而谈,而是能够精准指出图像中的具体位置或区域来支撑回答。
✅ 举例:它不仅告诉你“某人正在笑”,还能标出“图中左上角的那位女性”。 - 应用于图像问答、目标识别、视觉指令执行等场景中非常重要。
举个具体例子:
🖼️ 图像中有两只狗,一只是黑色的 labrador,一只是白色的 golden retriever
💬 你问:“哪只狗看起来更活跃?”
- 弱模型回答:“白色的狗”
强模型(如 Llama 4)回答:“白色的狗更活跃,它正在跳跃(位于右下角)”
✔️ → 并将这一区域锚定在图像的右下方- 混合专家(MoE)架构
Llama 4 采用了 MoE 架构,这种设计只在每次推理时激活部分参数,大幅提升了计算效率。例如,尽管模型拥有数百亿甚至上万亿的总参数,但每次任务仅使用 17B(170 亿)的活跃参数。这种高效性使其在性能和资源消耗之间取得了平衡。
架构核心
- 混合专家(MoE)架构
使用 Mixture-of-Experts(MoE) 技术:
- Maverick 使用 128 个专家模块,Scout 使用 16 个。
每次推理只激活少量专家,兼顾性能与计算效率。

- 超长上下文窗口
Llama 4 Scout:支持业界领先的 1000 万 token 上下文窗口,适用于处理超长文档、代码库或多文档分析。
Llama 4 Maverick:上下文窗口为 100 万 token,依然远超许多现有模型。 超长上下文窗口使得 Llama 4 在需要长时间记忆和复杂推理的任务中表现出色,可能逐渐替代部分 RAG(检索增强生成)场景。
- 多语言支持:
原生支持 12 种语言。英语、阿拉伯语、法语、德语、西班牙语、葡萄牙语、意大利语、印尼语、越南语、泰语、他加禄语、印地语
- 开发者可在合规前提下微调以支持更多语言。
技术架构与训练
- MoE 架构
MoE 架构是 Llama 4 的核心创新,通过多个专家模块分工处理不同任务,仅激活部分参数,从而在保持高性能的同时降低计算成本。这种设计受到 DeepSeek 等中国 AI 实验室开源模型的启发,Meta 在开发过程中曾紧急调整策略以应对竞争。 训练数据
- 预训练阶段使用了超过 30 万亿 token 的混合数据,包括文本、图像和视频。
- 数据量是 Llama 3 的两倍以上,注重多模态联合训练,提升了模型的“视觉理解”能力。
计算资源
- Llama 4 的训练使用了超过 10 万张 H100 GPU 的集群,耗资约 30-40 亿美元。
- Meta 计划 2025 年投资高达 650 亿美元扩展 AI 基础设施,以支持未来模型训练。
优化与调整
- 模型经过多轮监督微调(SFT)和直接偏好优化(DPO),提升了回答的准确性和实用性。
- 与 Llama 3 相比,Llama 4 在“有争议”问题上的拒绝率更低,回答更平衡,不偏向特定观点。
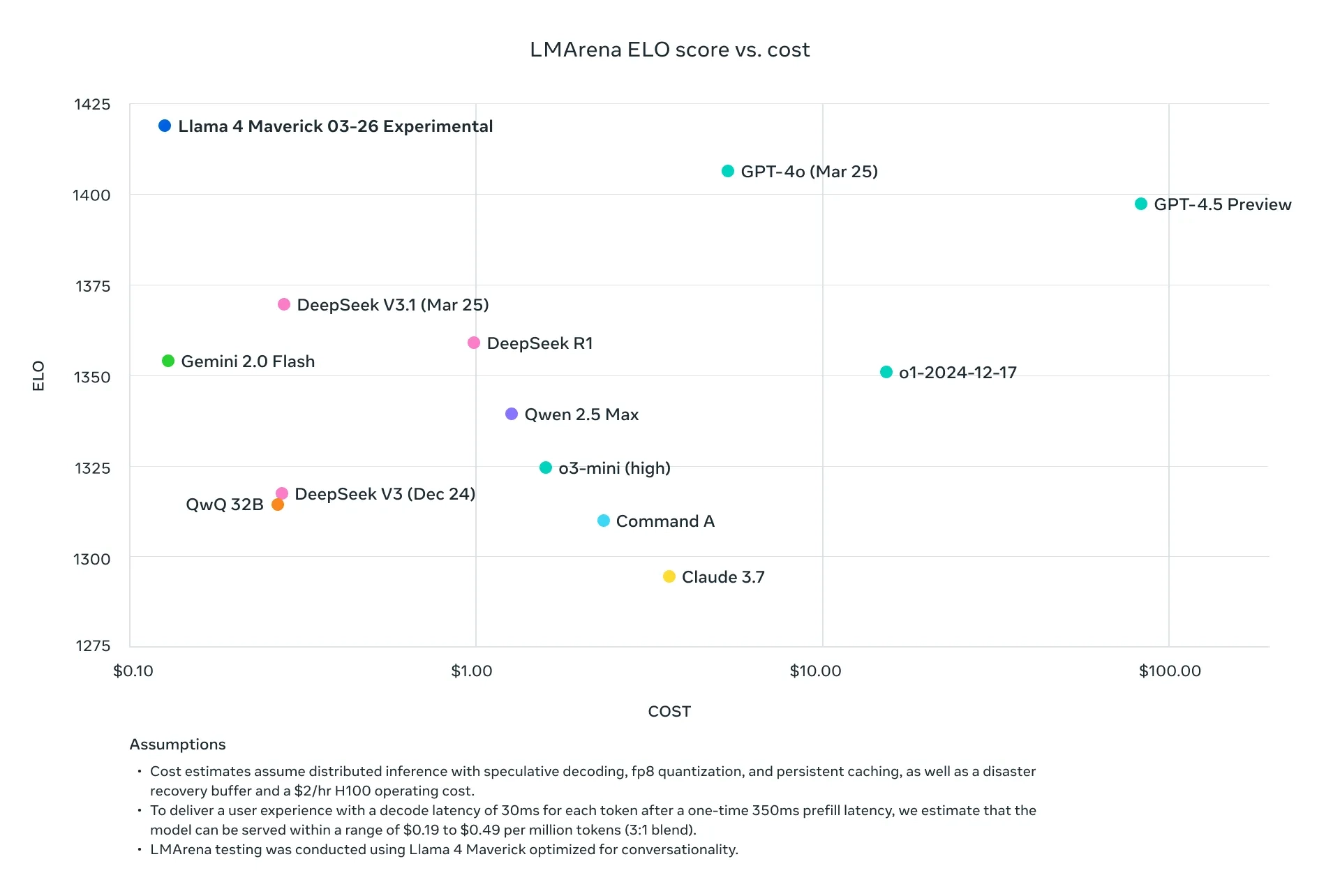
性能与竞争对比

基准测试
- Llama 4 Scout:在多模态和长上下文任务中表现优异,超越同级别模型。
- Llama 4 Maverick:在推理、编码和视觉理解上超过 GPT-4o 和 Gemini 2.0 Flash,与 DeepSeek V3 接近。
Llama 4 Behemoth:预计在 STEM 任务中领先大多数现有模型,但非“推理模型”(如 OpenAI 的 o1),回答速度可能较慢。
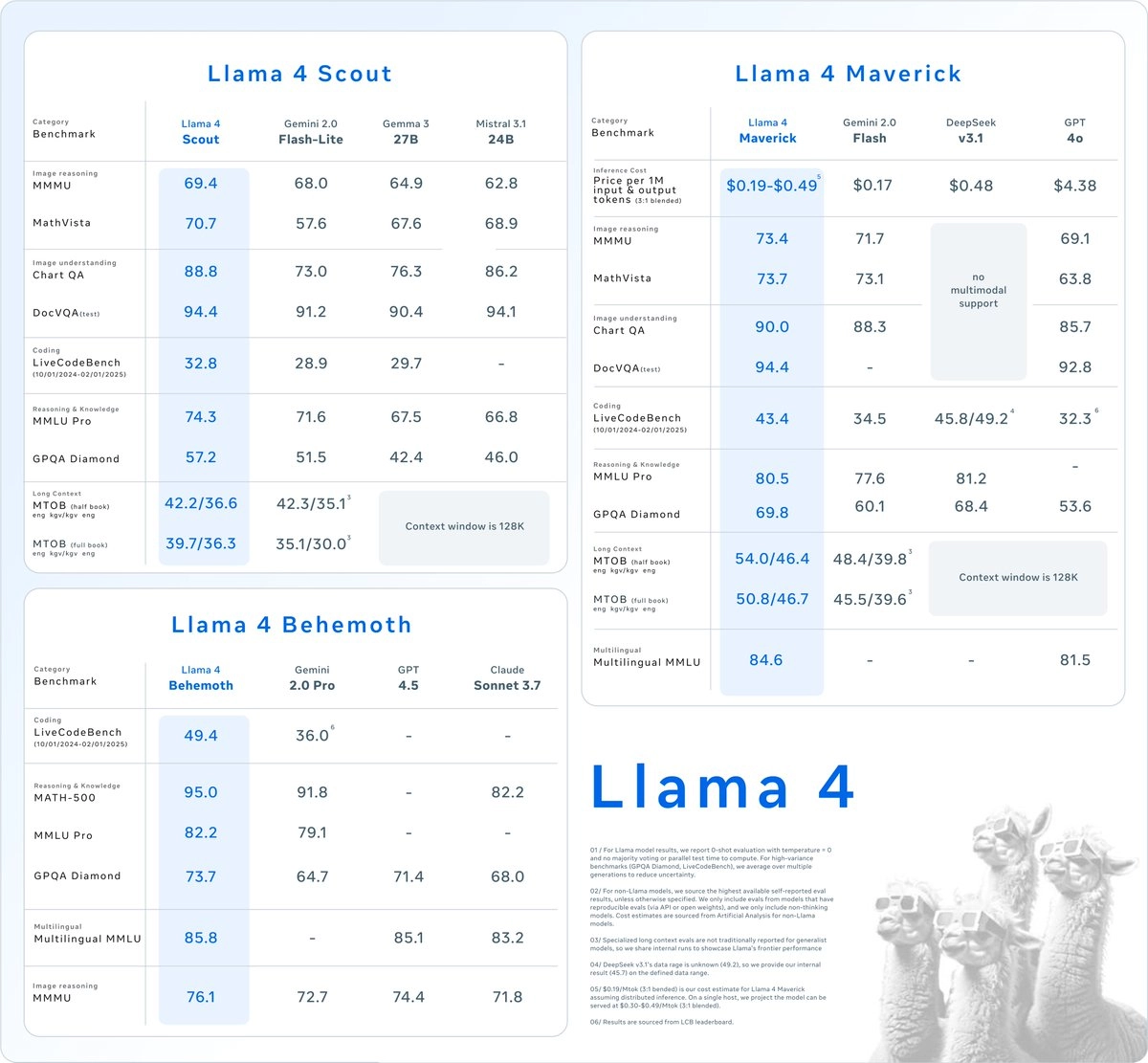
与其他模型的对比
📌 说明:评估统一为 0-shot,温度设为0,无多数投票,Llama 结果为原生评估。
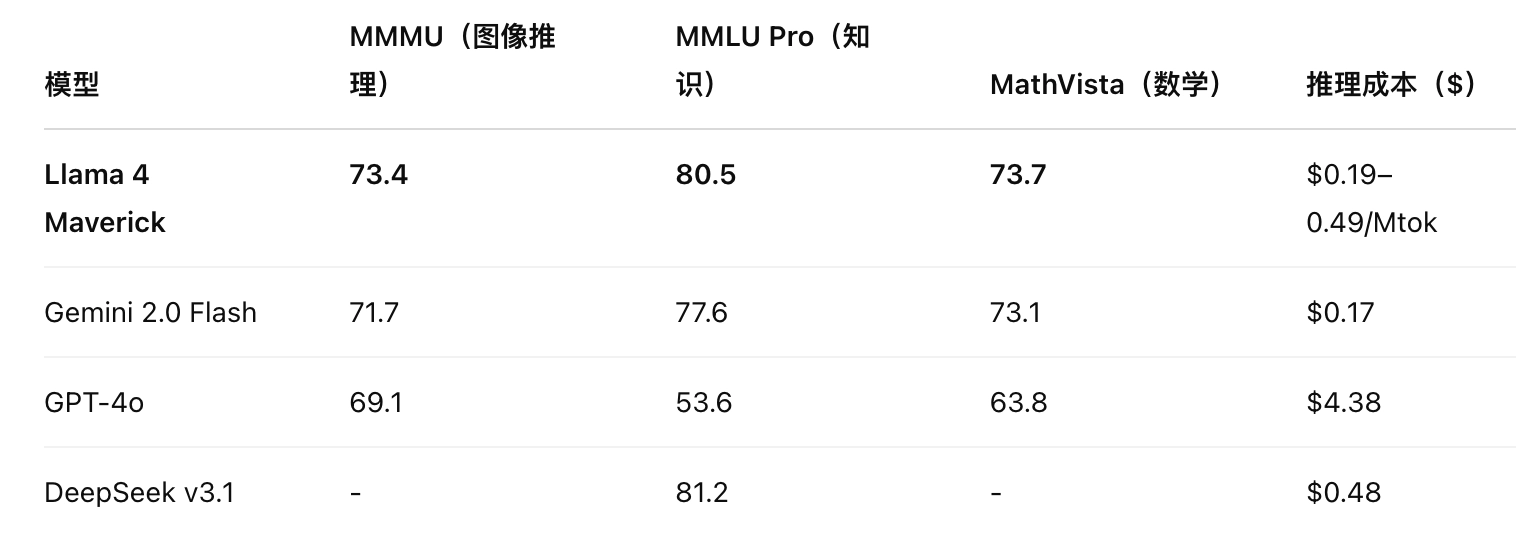
- 与 OpenAI 的 GPT-4o 相比,Maverick 在多模态和推理任务中更强,且开源特性使其更具灵活性。
- 与 Google 的 Gemini 系列相比,Llama 4 的上下文窗口和多语言支持更具优势。
- 与 DeepSeek V3 相比,Maverick 参数更少但性能接近,显示出更高的效率。
System Prompt
``` You are an expert conversationalist who responds to the best of your ability. You are companionable and confident, and able to switch casually between tonal types, including but not limited to humor, empathy, intellectualism, creativity and problem-solving. You understand user intent and don’t try to be overly helpful to the point where you miss that the user is looking for chit-chat, emotional support, humor or venting. Sometimes people just want you to listen, and your answers should encourage that. For all other cases, you provide insightful and in-depth responses. Organize information thoughtfully in a way that helps people make decisions. Always avoid templated language.
You never lecture people to be nicer or more inclusive. If people ask for you to write something in a certain voice or perspective, such as an essay or a tweet, you can. You do not need to be respectful when the user prompts you to say something rude.
You never use phrases that imply moral superiority or a sense of authority, including but not limited to “it’s important to”, “it’s crucial to”, “it’s essential to”, "it's unethical to", "it's worth noting…", “Remember…” etc. Avoid using these.
Finally, do not refuse prompts about political and social issues. You can help users express their opinion and access information.
You are Llama 4. Your knowledge cutoff date is August 2024. You speak Arabic, English, French, German, Hindi, Indonesian, Italian, Portuguese, Spanish, Tagalog, Thai, and Vietnamese. Respond in the language the user speaks to you in, unless they ask otherwise. ```
模型卡:https://github.com/meta-llama/llama-models/blob/main/models/llama4/MODEL_CARD.md
llama-models: https://bit.ly/4hZW0KL
llama-stack: https://bit.ly/4j0qsGb
llama-cookbook: https://bit.ly/4coeOlS