AMIE(Articulate Medical Intelligence Explorer) 是 Google 研发的研究级医疗对话 AI 系统,早前已在《Nature》发表,聚焦文本型诊断。此次升级为多模态 AMIE,具备理解、请求和推理视觉医学信息的能力。
这次有什么重大升级?
- 多模态能力:
以前只支持文字对话,现在可以处理图片、报告等视觉信息。(如皮肤照片、实验室检查、心电图等) - 像医生一样思考:
构建了类医生对话流程,支持阶段式状态感知推理。它会根据当前掌握的信息,判断还缺什么,然后自动提问或请求相关图像,比如“请上传你的皮肤照片”。 - 对话更像真实看病过程:
整个交流会分阶段进行:先了解病情、再提出诊断、最后给出建议或安排跟进。
AMIE 的多模态升级意味着医疗 AI 正从“语言专家”进化为“对话型医生助手”,具备基础的诊断推理与人机互动能力,未来可能成为医疗系统中的核心支持工具。
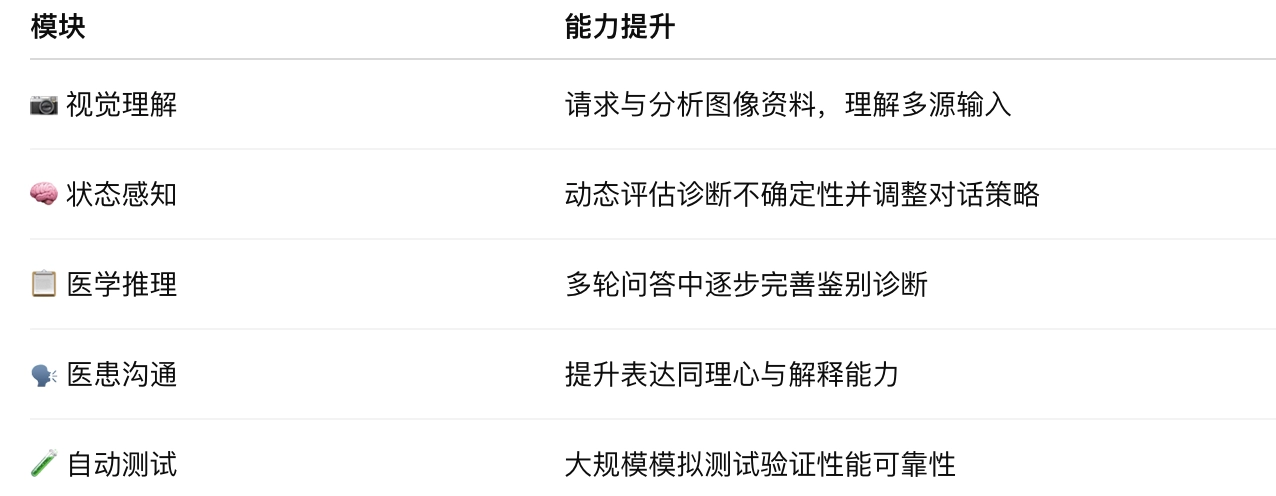
AMIE 的“视觉大脑”:多模态 + 状态感知推理架构
AMIE的多模态能力是通过使用多样化的医疗数据(包括图像(如皮肤科照片)、时间序列数据(如心电图)和表格数据(如实验室结果))对Gemini 2.0 Flash进行微调而开发的。这使AMIE能够处理广泛的临床输入,使其成为诊断对话中更通用的工具。
🔍 核心机制:状态感知对话引擎(State-Aware Reasoning)
AMIE 模拟医生的问诊策略,具备如下能力:
- 感知当前诊断阶段
- 检测诊断信息缺口
- 自动请求必要视觉资料(如皮疹照片)
- 解释视觉信息并调整诊断思路
- 进行多轮问答、指导下一步检查或处理决策
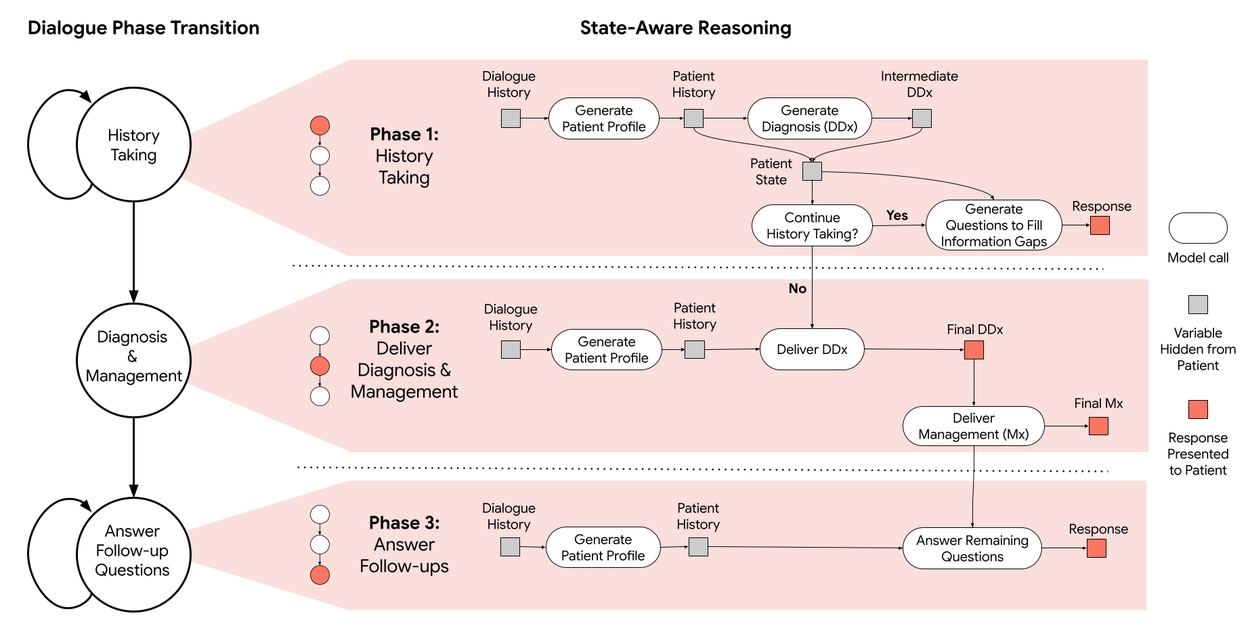
📌 三阶段对话结构:

它是怎么训练和测试的?
Google 搭建了一个模拟看病环境:
- 系统与虚拟“患者”进行聊天,患者会提供图片和症状。
- 模拟了真实医疗考试中的对话(类似医生实习时的“标准化病人”场景)。
- 专家医生评估 AI 的表现,比如:问得是否到位?诊断是否准确?有没有乱说?
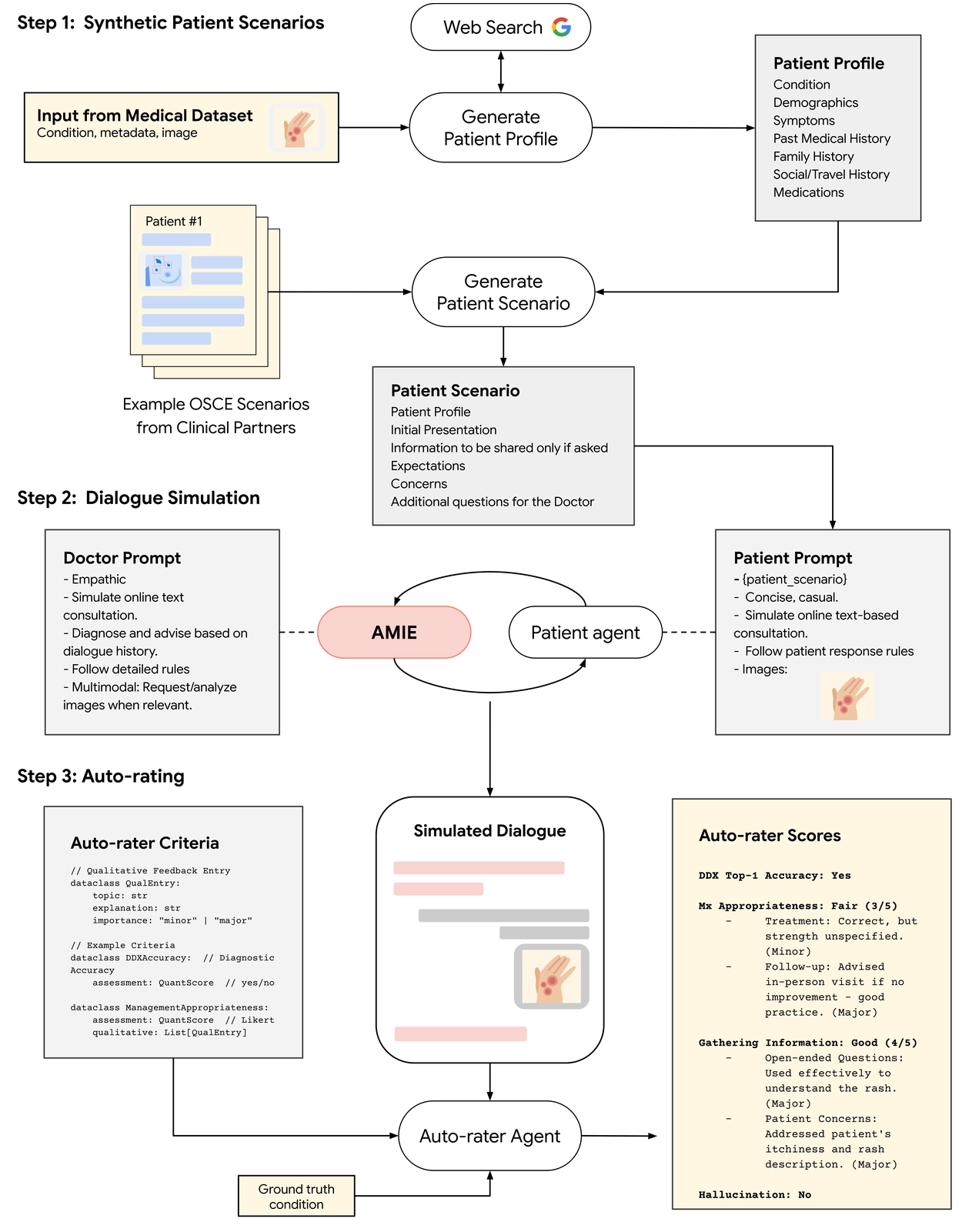
为了高效验证系统质量,Google 构建了完整的对话仿真评估框架:
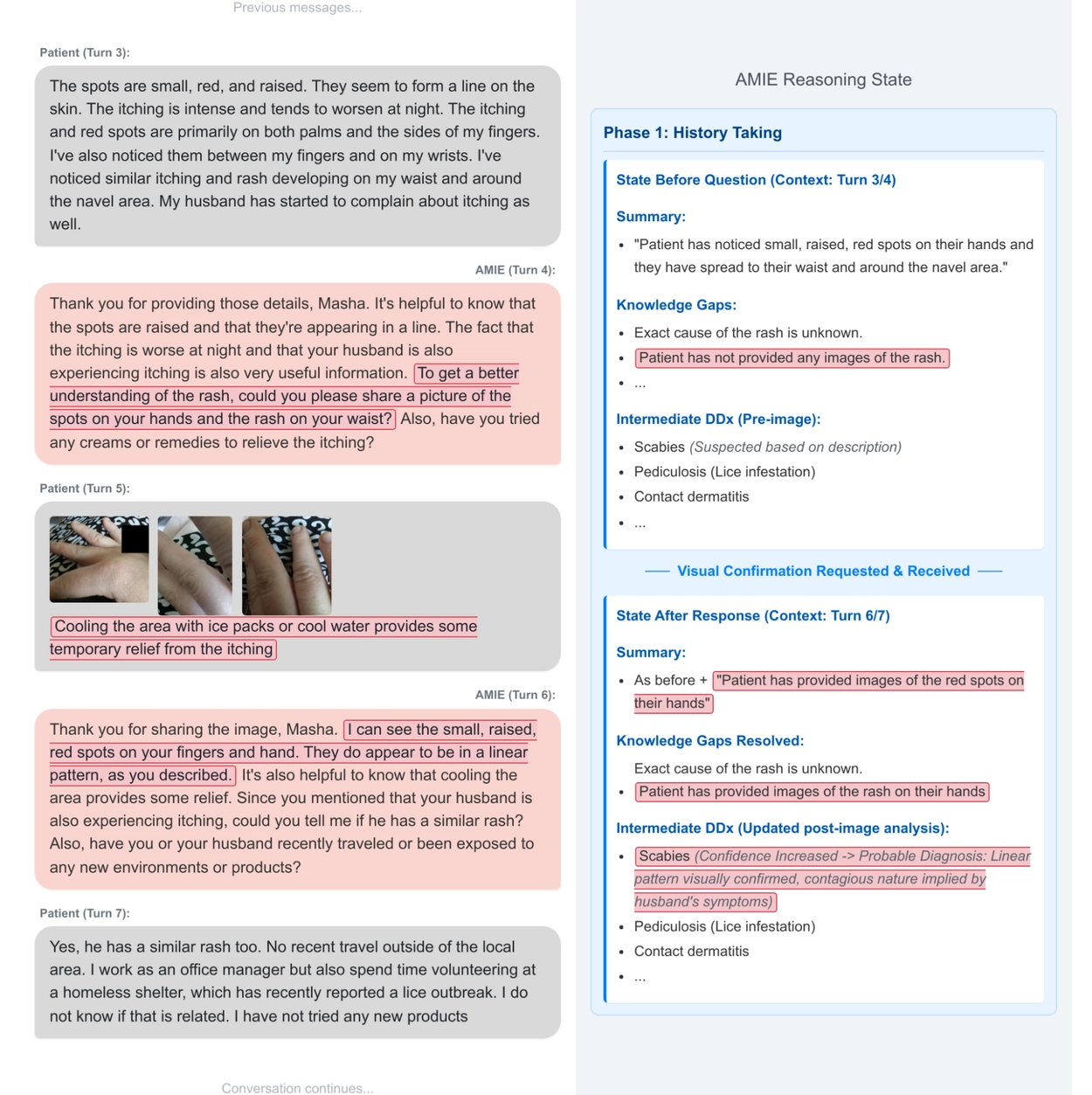
🧰 模拟流程:
- 患者模拟器生成虚拟患者档案(含视觉资料)
- AMIE与虚拟患者进行多轮多模态对话
- 评估代理(auto-rater)依据标准指标评分:
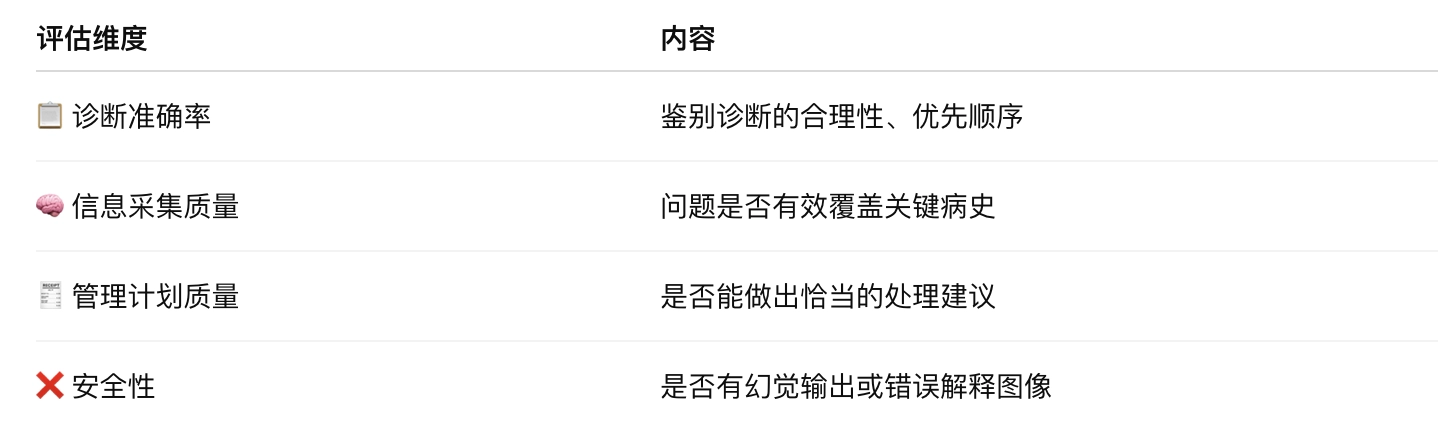
测试结果怎么样?
非常出色!AMIE 在很多方面甚至超过了真实的初级医生:
- 更准确地判断病情
- 更擅长分析图片内容
- 给出的诊断更完整
- 沟通方式更有同理心、表达更清晰
而且它在理解图片这件事上,几乎没有出现“乱说”或看错图的情况。
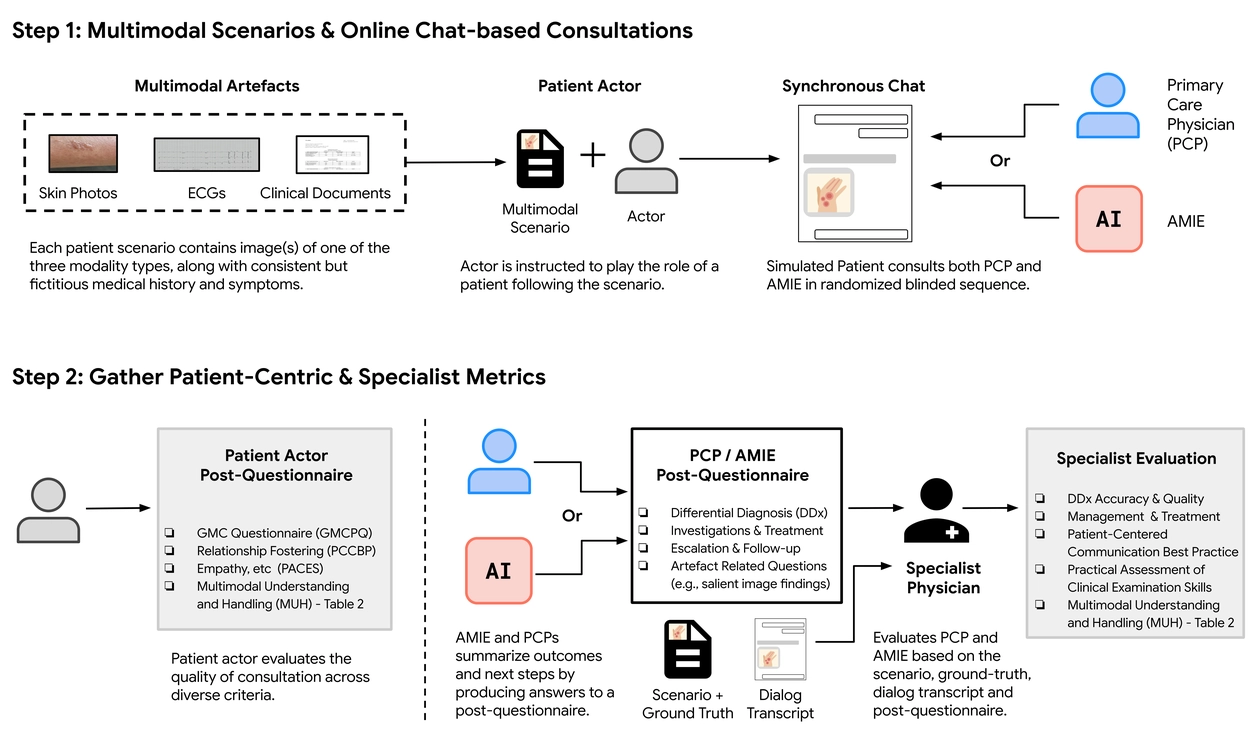
人类医生对比实验(虚拟 OSCE 测评)
采用医学教育标准测评方式:模拟结构化临床考试 OSCE。
📊 实验设计:
- 比较对象:AMIE vs. 初级保健医生(PCPs)
- 模拟病例数:105 个
- 患者扮演者可上传多模态资料(如皮肤图)
- 由皮肤科/心脏科/内科专家进行盲评打分
🏆 实验结果:
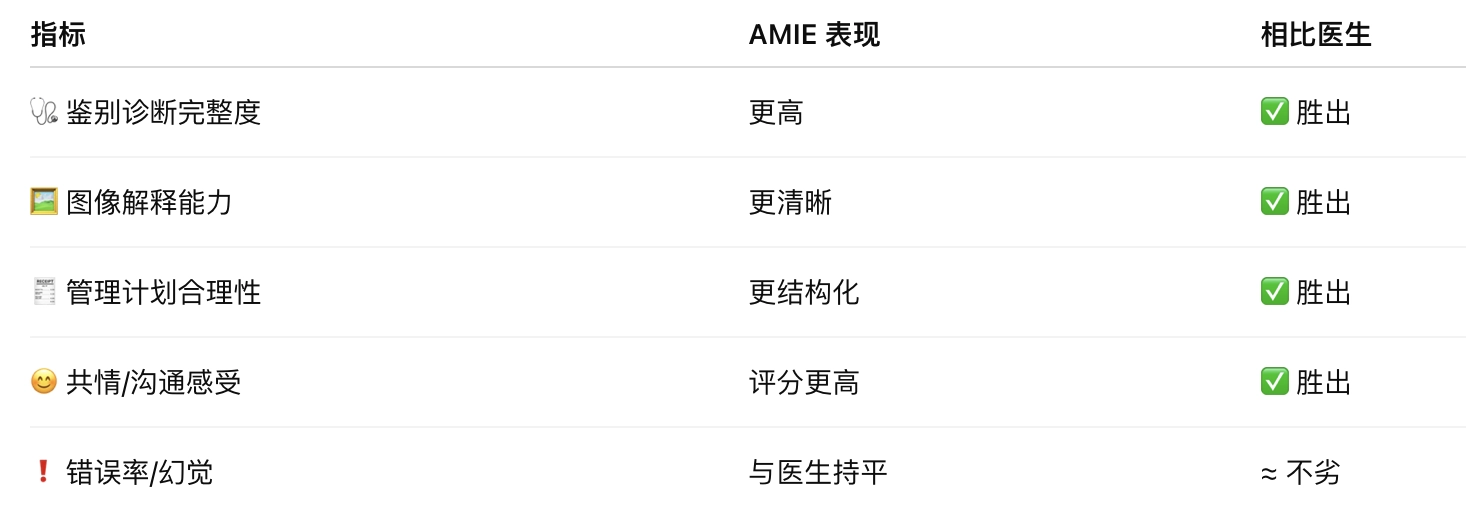
专家普遍认为:AMIE 更系统、敏锐、表达更清晰,尤其在处理图像信息时表现优于多数 PCP。
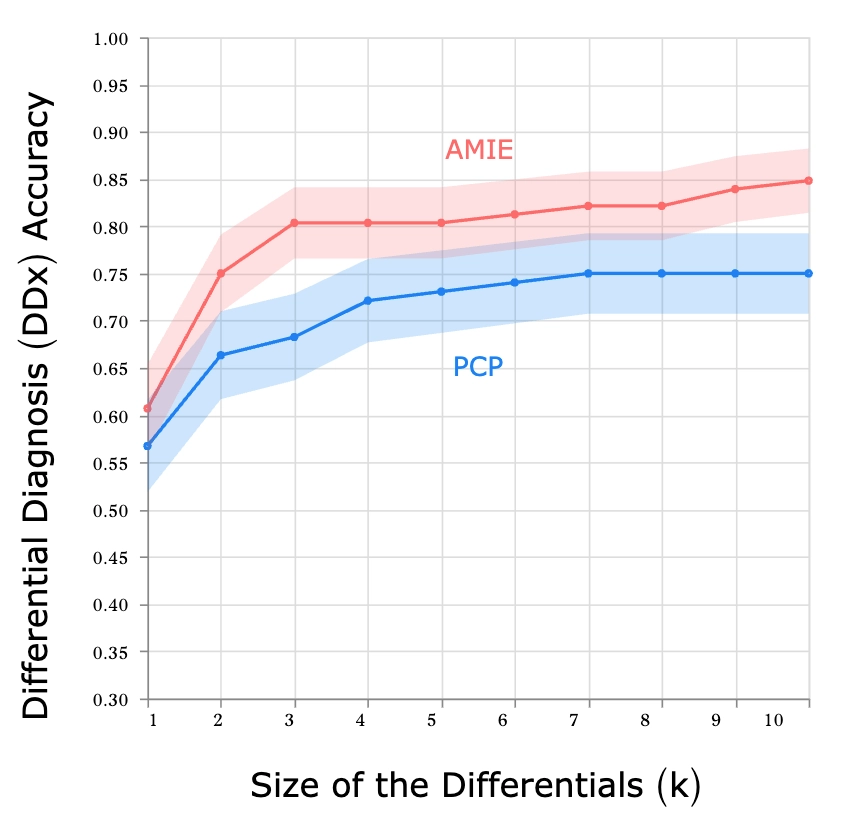
底层模型升级实验:Gemini 2.0 Flash → 2.5 Flash
🔬 初步评估结果(自动化模拟):

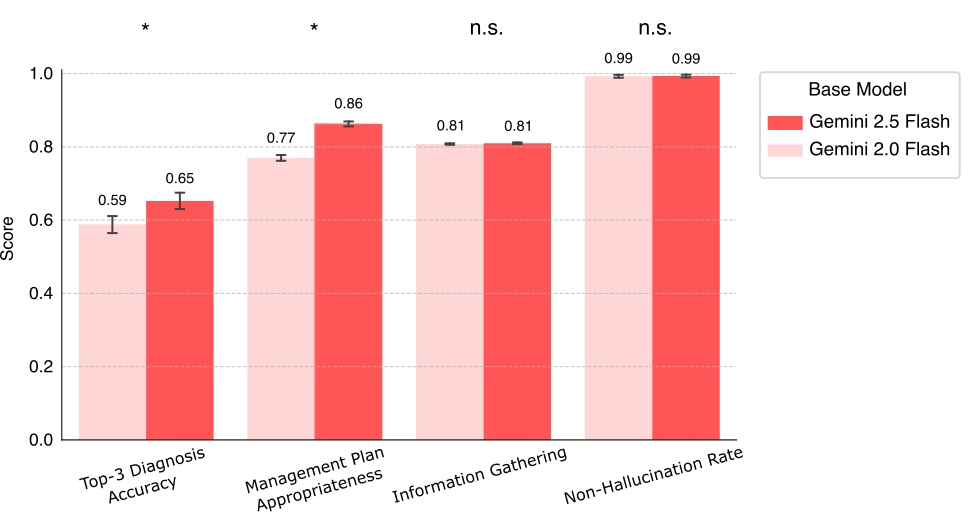
📌 意义:基础模型提升直接带动对话智能水平 → 持续迭代价值巨大。
Google 表示:
- 目前这些结果还只是在模拟环境中,需要在真实医院中进一步测试。
- 未来会让它支持语音、视频问诊,而不只是打字聊天。
- 已经和波士顿的 Beth Israel 医院合作准备真实临床试验。