小语言模型(SLM)怎么才能像大模型一样擅长“复杂逻辑推理”?
也就是说,在不增加参数数量(只用一个 3.8B 的小模型 Phi-4-Mini)的前提下,让它在数学等高要求推理任务中表现得像个“聪明的大脑”。
🧭 为什么这个问题重要?
目前很多AI助手(比如GPT)能回答问题、讲道理,但它们往往参数量很大(几十甚至几百亿个参数),部署成本高。而小模型如果也能推理,意味着:
✅ 更省资源(可部署到本地、移动设备)
✅ 更快响应、更低延迟
✅ 更易部署在企业或边缘设备中
微软提出并验证一套 面向SLM的多阶段推理增强训练方案,用于显著提升数学推理能力,并在 3.8B 参数的 Phi-4-Mini 模型上实现 SOTA 性能。
- 用途定位:为边缘计算、移动设备等设计,强调低资源环境下的推理性能。
- 训练方式:对 Phi-4 进行监督微调(SFT),使用 o3-mini 生成的高质量推理数据。
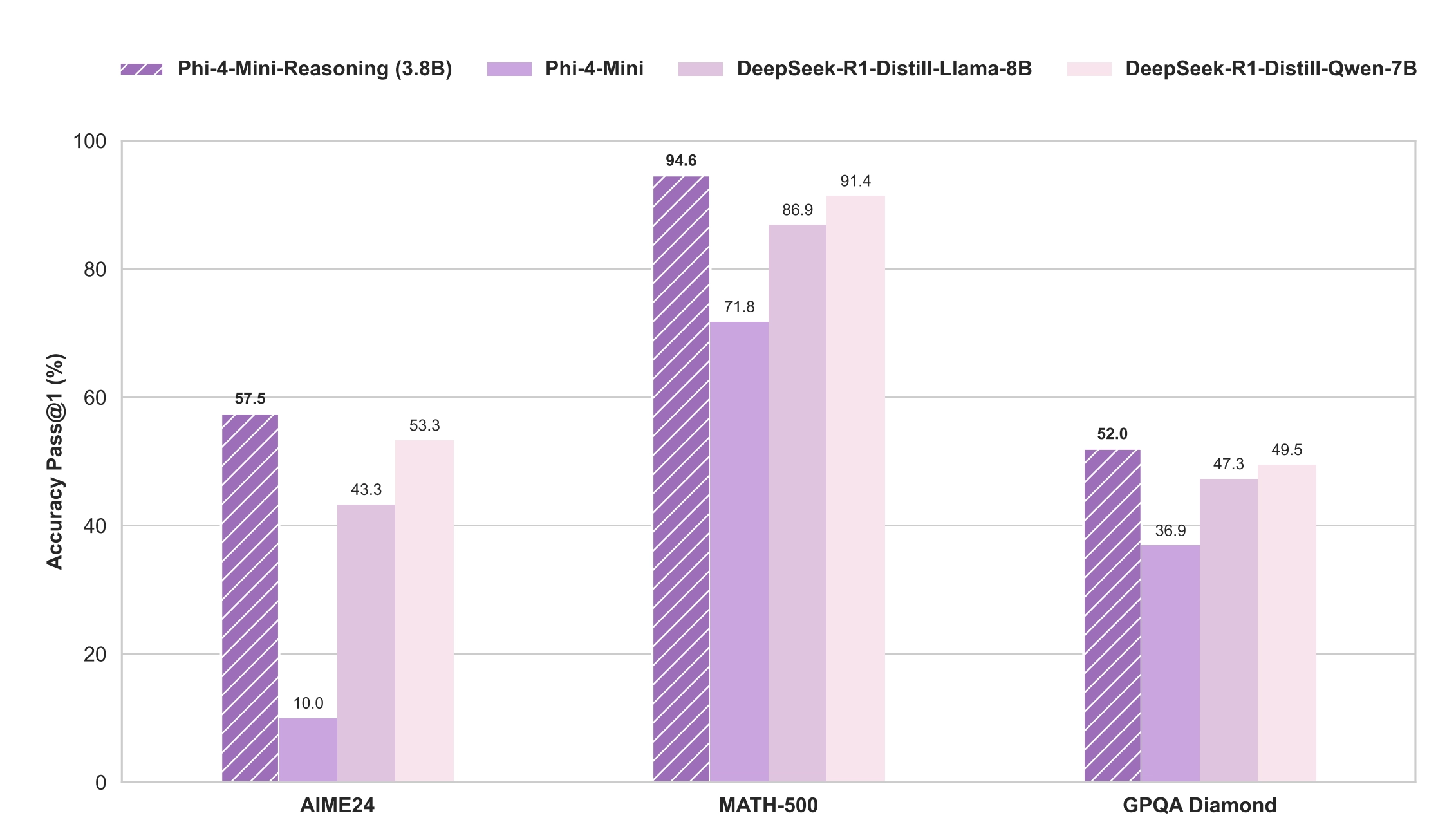
- Phi-4-Mini-Reasoning 凭借 3.8B 的小模型体量,在多个指标上超越了 7B 甚至 8B 的模型。
在数学与科学推理基准中取得优异成绩:
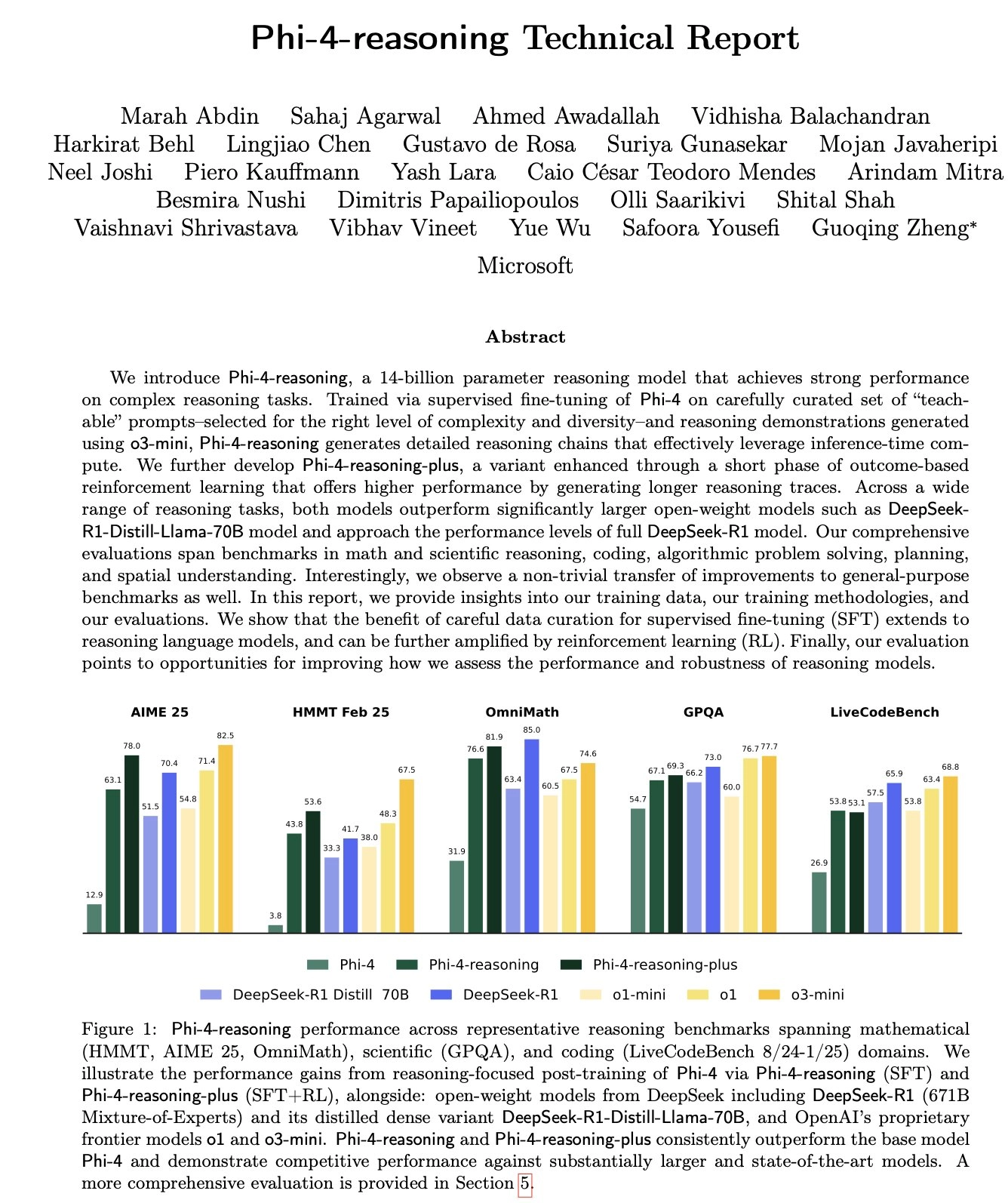
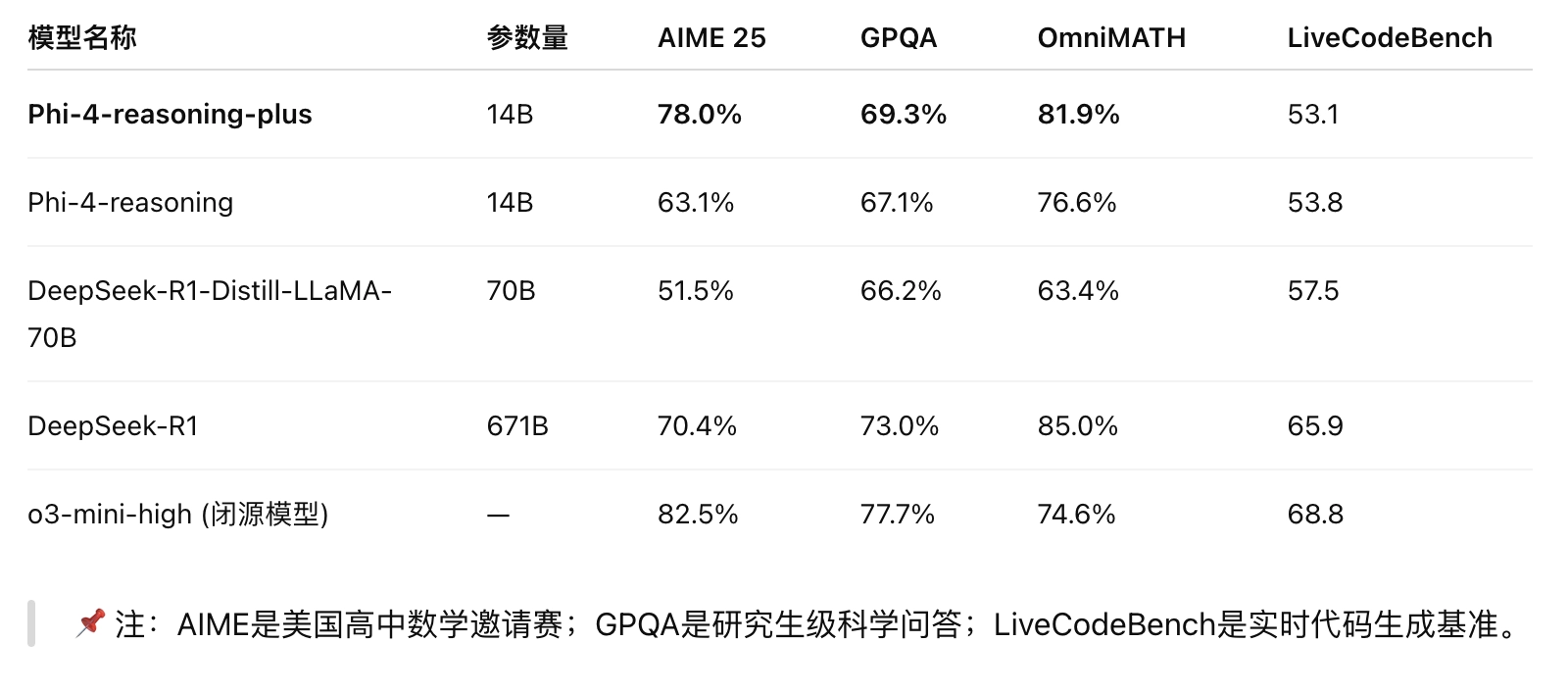
- Phi-4-Reasoning 和 Reasoning-Plus 超越 Llama-70B、DeepSeek-R1-Distill,在 AIME 2025 等基准测试中甚至优于 671B 的 DeepSeek-R1。
- Mini-Reasoning 凭 3.8B 参数超越了多款 7B 以上模型,如 OpenThinker-7B、Llama-3.2-3B、Stratos-7B 等。
- 应用场景:教育场景、嵌入式辅导系统、Copilot+ PC 本地部署。
模型介绍
模型家族:Phi-4-Reasoning、Phi-4 Reasoning-Plus、Phi-4 Mini Reasoning
🧠 Phi-4-Reasoning
- 简介:基于 Microsoft 的 14B 参数小语言模型 Phi-4,通过**监督微调(SFT)**专门训练于复杂推理任务。
主要特点:
- 能生成结构化的推理链
… 。 - 表现接近甚至超越大模型(如 DeepSeek-R1-Distill-70B)。
- 能生成结构化的推理链
- 擅长领域:数学推理、科学问答、算法题、计划安排。
- 适用场景:需要强推理但资源受限的服务器或API服务。
🧠🧪 Phi-4-Reasoning-Plus
- 简介:在 Phi-4-Reasoning 的基础上,通过**强化学习(RL)**进一步优化,追求更高推理准确率。
主要特点:
- 使用更多 token(约 1.5 倍)进行更深入的推理。
- 推理准确率明显优于基础版 Phi-4-Reasoning。
- 擅长领域:高难度数学题、复杂多步骤问题。
- 适用场景:对推理质量要求极高的研究、竞赛型应用。
⚡️ Phi-4-Mini-Reasoning
- 简介:轻量级推理模型,仅 3.8B 参数,专为低资源环境设计(如移动端、本地运行)。
主要特点:
- 推理能力优于多数同规模(甚至更大)模型。
- 可运行于 Windows 11 本地、Copilot+ PC 的 NPU 上。
- 擅长领域:数学问题(初中至博士级)、教育类任务。
- 适用场景:教育辅导、嵌入式设备、离线 Copilot 功能。
数据与训练方法
数据构建:
- 精选超过 140 万个“可教”提示(teachable prompts),涵盖数学、科学、编程、安全等领域。
- 响应由 o3-mini 模型合成,带有
和 标签的结构化推理链。
- 去污染(decontamination):训练数据通过算法手段排除与主流基准数据(如 AIME-2024、MATH 等)的重合。
模型架构调整
- 扩展最大上下文长度至 32K token。
- 使用两个占位符 token(
与 )标记推理块,支持结构化思考链条。
强化学习(Phi-4-Reasoning-Plus)
- 使用 Group Relative Policy Optimization(GRPO)进行强化学习,仅用约 6400 个数学问题。
怎么让小模型变聪明的?
他们不是只靠“堆数据”或者“提个好提示”,而是设计了一个四步走的完整训练方案,让模型“从不会推理”逐渐“学会推理”。
四阶段设计保障训练稳定性与能力提升:
- Mid-training 蒸馏(大规模打基础)
- 精调微调(专注高难推理)
- 偏好优化(学会区分好坏推理)
- 强化学习(通过奖励机制进一步提升)
🧩 步骤1:让模型先熟悉“怎么推理”(叫 Mid-training)
类比:像小学生先看很多解题过程,理解别人是怎么一步步解题的。
- 用大模型(如 DeepSeek-R1)自动生成 上百万条“题目 + 解题过程”
- 只保留 答案正确 的样本,用于训练小模型“模仿这种推理方式”
- 覆盖了数学的多个难度(从小学到大学)
- 模型就像预习了大量“做题思路”
🧩 步骤2:精细化训练(Supervised Fine-tuning)
类比:选出最经典的例题,反复重点讲解,提升理解深度。
- 从上一步中筛选 高质量+难度高的题目
- 训练模型不光要“会解”,还要学会“什么时候该停下”
- 不再打包训练,而是逐例学习,让它更专注、精准
🧩 步骤3:从“错误答案”中学习(Rollout Preference Learning)
类比:让学生自己对比两个解题过程,学会“哪个更好”。
- 使用之前被扔掉的 错误答案 来构建“优 vs 劣”的对比样本
- 教模型学会“哪个回答更好”而不仅是“哪个对”
- 训练方式叫 DPO(Direct Preference Optimization)
🧩 步骤4:用奖励机制强化(Reinforcement Learning)
类比:答对题有奖励,答错题扣分,反复练习最终得高分。
- 如果AI的回答“最终答案对” → +1 分;否则 -1 分
- 使用类似游戏中“策略优化”的方法(如 PPO、GRPO)强化模型的答题策略
引入一系列技巧来 避免训练不稳定:
- 控制输出长度差异;
- 平衡正负样本;
- 逐步降低“探索性”(温度退火)
📊 效果到底怎么样?
Benchmark 任务表现(Pass@1 准确率)

几个关键领域的表现亮点
📘 数学推理(AIME, OmniMath)
- Phi-4-reasoning-plus 在 AIME 2025 上取得了 78% Pass@1,超越 DeepSeek-R1(70.4%)。
- 在 OmniMath 上达到 81.9%,为开源14B模型中的领先水平。
🔬 科学推理(GPQA)
- 在研究生级科学题中(GPQA Diamond),达到 69.3%,几乎追平 DeepSeek-R1(73.0%)。
- 比 QwQ-32B(59.5%)和 DeepSeek Distill-70B(66.2%)表现更好。
💻 编码能力(LiveCodeBench)
在代码生成任务上保持与基础模型相当性能(~53%),但未特别优化(未用于 RL 阶段训练)。
在 NP 难度问题如 3SAT、TSP、日程规划(BA-Calendar)中都有 30~60% 的性能提升;
显示出 模型具有广泛迁移的推理能力,即使这些任务没出现在训练集中。
Phi 4 mini在 三个数学类测试集 来考察训练效果:
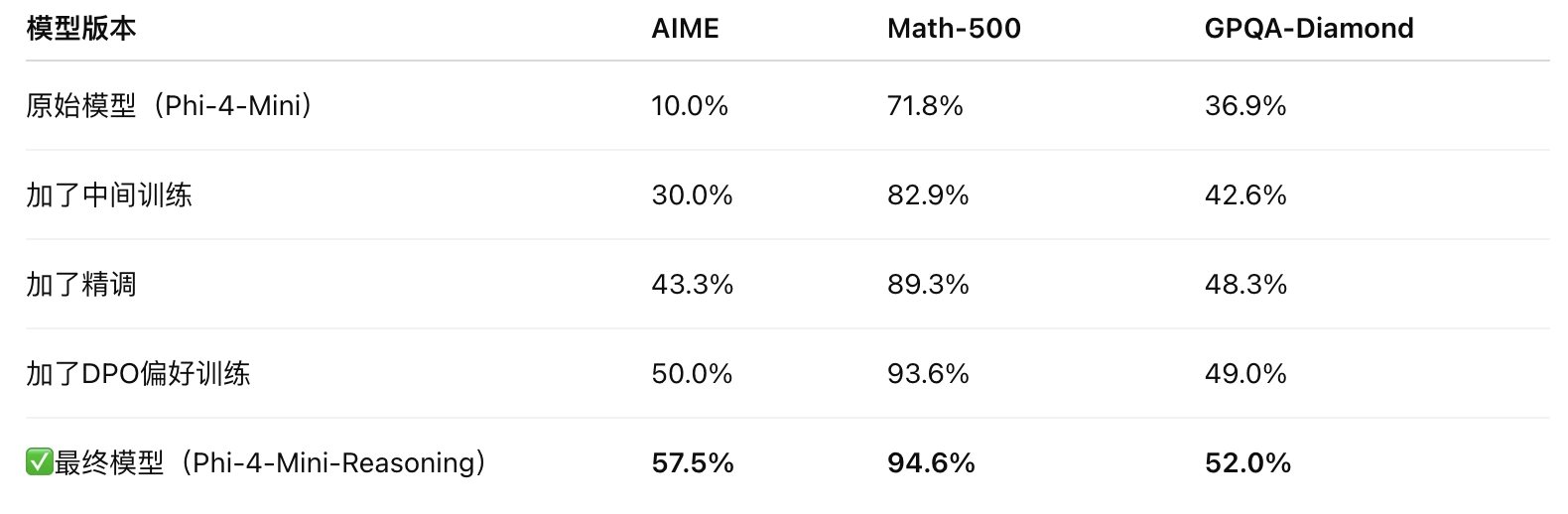

- ✅ 小体量大性能:Phi-4-Mini-Reasoning 凭借 3.8B 的小模型体量,在多个指标上超越了 7B 甚至 8B 的模型。
- ✅ 对数学推理任务特别强:在 Math-500 上达到 94.6%,接近 GPT-4 级别的表现。
- ✅ 训练策略效果显著:逐步蒸馏 + 偏好学习 + 强化学习使性能逐步攀升,训练路径清晰、贡献明确。
- ✅ 适合低资源部署场景:性能强大但资源消耗低,适合本地私有化部署、移动端、教育应用等。
重要发现与结论
数据质量与组合的重要性:
- 训练数据的精心选择(包括种子问题的筛选和生成长链推理)对于提升模型的推理能力至关重要。
- 模型通过特定领域的训练后,可以将推理能力泛化到未专门训练的领域(例如规划和NP-hard问题)。
推理能力与泛化性:
- 尽管模型的强化学习阶段只使用了数学领域的数据,但泛化能力显著增强,算法规划、NP-hard问题求解和其他复杂任务性能显著提高。
推理长度与准确性权衡:
- Phi-4-reasoning-plus倾向于生成更长的推理过程,这通常能提升数学任务的准确性,但也会带来计算成本增加的问题。Phi-4-reasoning 在推理长度和准确性之间的权衡则更为平衡。
- 评测方法的改进建议:
技术报告:https://arxiv.org/abs/2412.01951
模型下载:https://huggingface.co/microsoft/Phi-4-reasoning
官方介绍:https://azure.microsoft.com/en-us/blog/one-year-of-phi-small-language-models-making-big-leaps-in-ai/