Google 近期推出的 Gemini 2.5 Pro(I/O预览版 0506)和 Gemini 2.5 Flash 两款模型,代表当前 Google 在多模态 AI 尤其是**视频理解(video understanding)**方向的最前沿进展。
Gemini 2.5 是全球首个具备原生视频处理能力,能够理解、分析、转化视频为结构化应用内容的通用多模态模型。
🚀 与前代和同类模型对比:
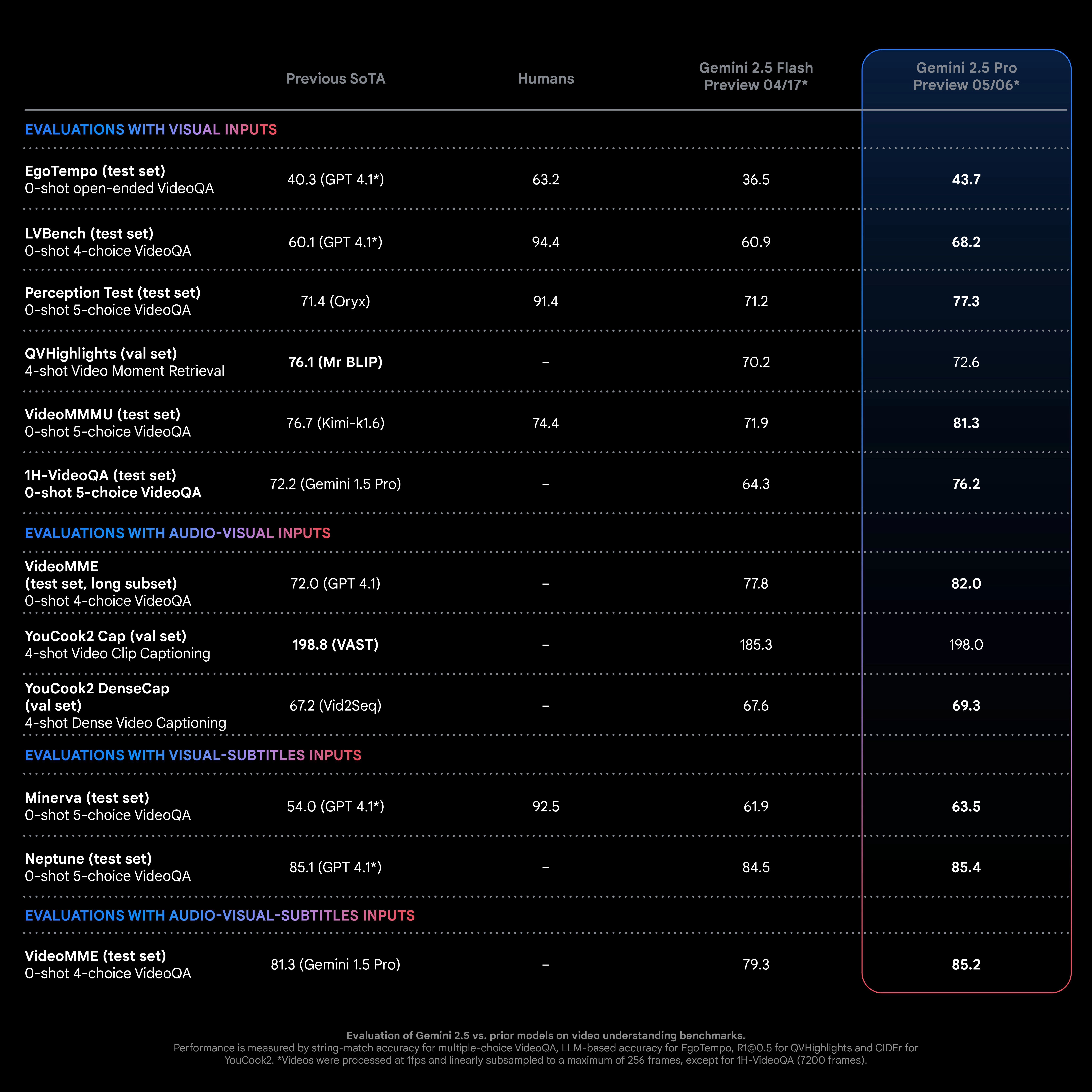
- 与 GPT-4.1 相比:在相同任务设置和输入条件下(统一的 prompt + 视频帧输入),Gemini 2.5 Pro 在多个视频理解任务中实现领先。
- 与微调专用模型相比:在 YouCook2(视频密集字幕)、QVHighlights(视频片段定位)等任务中,无需专用微调即可逼近或超越性能。
- Flash 版本:适用于资源受限场景,成本更低,性能与 Pro 相近。
Gemini 2.5 支持并行处理以下输入类型:
- 📽️ 视频(最高可处理 7200 帧/6 小时)
- 🔊 音频(语音分析、事件识别)
- 🧾 文本(prompt、字幕、标题等)
- 🧑💻 代码(生成器/应用指令)
支持任务类型广泛:
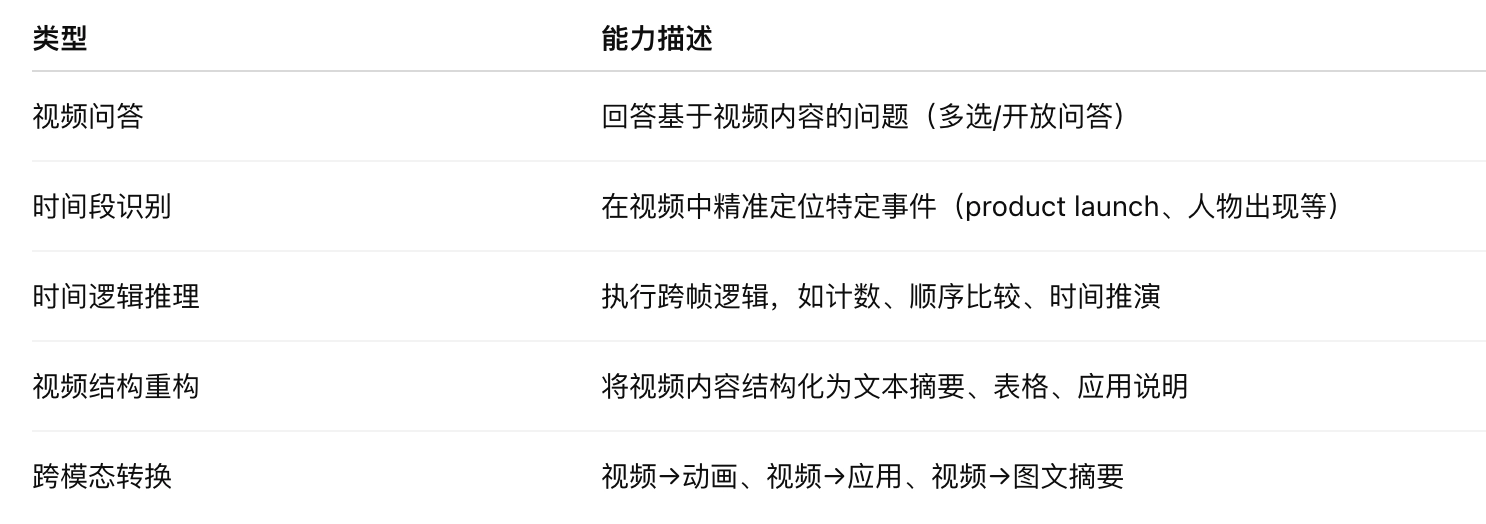
视频理解能力展示
✅ 1. 视频到学习应用(Video → App)
流程:
- 输入 YouTube 链接 + 任务说明
- 模型分析视频 → 生成学习应用的规范说明文档
- 再将规范转化为代码(如教学小程序)
🔎 应用场景:
- 自动生成可交互教程、模拟器、可操作 PPT 等教育工具
✅ 2. 视频转动画(Video → p5.js Animation)
输入视频 + 提示(如“可视化其中出现的所有地标”)
→ Gemini 2.5 分析视频帧顺序,生成与内容结构对应的 JS 动画(基于 p5.js)。
🔎 应用场景:
- 信息可视化、快速摘要演示、会议纪要图形化
✅ 3. 瞬时片段定位与分析(Moment Retrieval)
通过音视频结合分析,Gemini 2.5 可:
- 准确识别演讲/视频中多个内容高密度片段
- 输出每段起止时间 + 主题标签
📌 示例:在 Google Cloud Next 2025 开场演讲视频中自动识别出 16 个产品发布相关的子片段。
✅ 4. 复杂时间推理(Temporal Reasoning)
支持对视频中跨时间跨度的事件发生情况进行统计与逻辑判断。
📌 示例:统计视频中主角使用手机的次数,准确识别并计数 17 次。
如何使用
Gemini 2.5 Flash 和 Pro 中的视频理解功能现在可在 Google AI Studio 、 Gemini API 和 Vertex AI 中使用。Gemini API 和 Google AI Studio 提供对 YouTube 视频的支持,使任何人都可以构建可访问数十亿个视频的应用程序。
- 支持低清视频处理,能够处理约 6 小时的视频
- 最高支持 200 万 token 上下文
- 极具竞争力的视频理解性能(在 VideoMME 上,准确率为 84.7% vs 85.2%)。
- API 中支持直接解析 YouTube 链接
- 适配教育、知识管理、自动化创作等 SaaS 开发场景
在线体验【视频转学习应用程序】:https://aistudio.google.com/u/1/apps/bundled/video-to-learning-app?showPreview=true