在 2025 年的 Google I/O 大会上,Google 对外展示了旗下 AI 助手产品 Gemini 的一系列重大升级。
此次更新覆盖了搜索交互、视觉识别、内容生成、办公集成、信息处理、图像与视频创作等多个核心场景,全面体现了 Gemini 从“聊天机器人”向“多模态 AI 工作平台”的演进。
Google 的目标非常明确——将 Gemini 打造为“最个性化、最主动、最强大的 AI 助手”。
一、打造“更懂你”的个性化助手
Gemini 正式引入更深层的个人上下文能力。除了已有的 搜索历史关联 功能外,未来用户在获得许可的前提下,还将可以整合 Gmail、Google Drive、日历、Keep 等 Google 应用中的信息,为 Gemini 提供“关于你的一切”上下文,进一步提升回应的个性化和相关性。
这标志着 Gemini 正从一个被动应答系统进化为一个“持续感知你生活”的 AI 伙伴。
二、Gemini Live:视觉+语音,现场解决问题
在真实世界中,我们常常希望“指着东西问 AI”,而现在,这成为现实。
Gemini Live 具备强大的视觉和屏幕共享功能,用户可以直接通过摄像头或屏幕分享,让 AI 帮助识别问题、提供方案。该功能从 5 月 20 日起已向 Android 和 iOS 用户开放,并将逐步推广。
此外,Gemini Live 即将与 Google 日历、Keep、任务、地图等服务打通。例如,用户可以直接对准活动海报,说一句“添加到我的日历”,Gemini 就能自动解析信息并完成添加。
三、Deep Research:更强的文档分析工具
Gemini 在研究与分析功能上也迎来重要更新:
- 支持文件与图片上传:用户可将 PDF、图像、Word 文档等拖入对话中,Gemini 即可进行内容理解、总结、对比。
- 集成 Gmail 与 Google Drive(即将上线):允许 Gemini 在用户授权下,从邮件和云端硬盘中提取相关数据,进行多文档比对与智能回答。
这大幅增强了 Gemini 在办公场景下的“信息聚合与分析能力”。
四、Canvas 内容生成:聊天记录秒变网页/播客/测验
Canvas 是 Gemini 的一项多模态创作工具,如今迎来大升级:
- 新增“Create”按钮,用户无需再输入提示词,只需基于当前对话内容,即可自动生成互动内容。
- 支持一键将 Deep Research 的输出内容转换成 网页、播客音频、互动测验 等多种形式。
- 适合营销、教育、自媒体等场景,节省创作流程的每一步。
这不仅是 AI 辅助写作,更是 AI 主动策划与发布。
五、Gemini for Chrome:浏览器中的 AI 伴侣
Google 将 Gemini 深度集成至 Chrome 浏览器中,推出了“浏览助手”功能:
- 用户可在任意网页中点击 Gemini 图标,输入或语音提问。
- 可实现网页摘要、术语解释、跨页面问答等功能,无需切换标签页。
- 减少页面跳转,告别标签页地狱
- 初期将在美国地区的桌面版 Gemini 订阅用户中推出。
这是 Google 正在推动的“无边界助手”策略,即任何软件界面中,AI 都应无缝嵌入、随时响应。
六、Imagen 4:图像生成更进一步
在图像生成方面,Google 推出了升级版模型 Imagen 4,带来:
- 更清晰、细腻的图像细节
- 更自然丰富的色彩呈现
- 更可靠的文字与标注生成
- 人物面部、衣物纹理、背景构图等视觉表现均达到新高度。
Imagen 4 现已开放所有 Gemini 用户免费使用,无需订阅即可体验高质量图像创作。




七、Veo 3:迈向电影级视频生成
除了图像外,Google 还发布了全新的视频生成模型 Veo 3:
- 支持生成高清视频(最高可达 4K 分辨率)
- 可添加音效、背景噪音、对白台词
- 理解更复杂的叙事逻辑与动态场景
Veo 3 意味着 Gemini 不再只是图文助手,也正在成为“影像创作者的 AI 导演”。
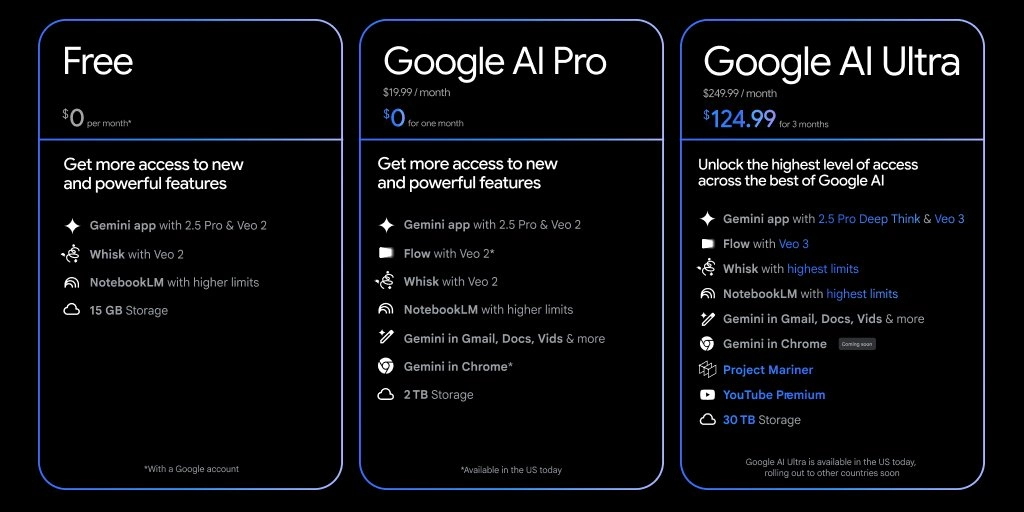
八、全新订阅体系:Google AI Pro 与 Ultra
为满足不同用户的深度使用需求,Google 推出了新的 AI 订阅层级:
- Google AI Pro:面向日常进阶用户
Google AI Ultra:为高阶创作者与专业工作者打造,提供:
- 更高的使用频率与上下文长度
- 更快的响应速度
- 提前试用如 Veo 3、Imagen 4 等最新模型
Ultra 明显对标 OpenAI 的 GPT-4 Turbo 付费用户,展示出 Google 在高端 AI 市场的野心。
Gemini 正成为一个“AI 操作系统”
此次 Google Gemini 的系列升级,不再局限于聊天问答或网页助手,而是全面走向一个整合视觉、语言、内容、工具、行为的“AI 工作中枢”。
Gemini 不仅要“回答问题”,更要“处理任务”、“整合上下文”、“生成成果”、“提出建议”,未来可能成为个人工作流中的“AI 执行官”。
Google 正在以惊人的速度和广度推进 AI 产品落地,Gemini 的每一次迭代,都是一次对“未来办公形态”的提前预演。
其他更新内容
Google Meet 新增实时 AI 同声传译功能
Google Meet 引入 AI 语音翻译,初步支持英语和西班牙语对话。最重要的是:
- 保留用户原有声音、语调与语气,换语言不换风格
- 类似电影配音技术自动同步内容
这是 AI 在语音领域的关键进展,不仅限于听懂,而是“实时翻译 + 仿声合成”,接近真正的 AI 同声传译员。
✅ 跨语言会议变得自然无缝,极大拓展远程协作能力。
Flow:AI 驱动的电影工作室横空出世
Google 推出了全新的创作平台 Flow:
- 将 Veo(视频)、Imagen(图像)、Gemini(脚本与角色)无缝整合
- 保持人物形象、风格、背景在不同镜头中的一致性
- 独立创作者可一人制作全片内容(含动画、对白、风格)
这不只是视频生成,而是完整的“AI 叙事平台”,相当于 Midjourney + ChatGPT + Runway + Premiere 的融合体。
✅ AI 让影视内容创作进入个体规模化阶段。
未来预告:Agent Mode、Project Mariner、多端 API 打通
- Agent Mode: Gemini 将能主动执行任务,如填写表单、处理网页内容等
- Project Mariner 多任务 AI 模块(优先面向美国地区 Ultra 订阅用户)
- Gemini API 支持桌面功能调用,即 AI 可以操作电脑软件、文件、命令等
这些是构建“AI 使用电脑”的雏形,等同于 GPT-4 + AutoGPT + 电脑自动化脚本结合。
✅ 从聊天 AI → 操作型智能代理的质变。
Android XR 智能眼镜首次公开演示
Google 展示了原型版 Android XR 智能眼镜:
- 实时翻译、导航、任务提示
- 与 Gemini 整合,实现真正的视觉助手
- 类似苹果 Vision Pro,但更贴近日常生活与实用场景
这标志着 Google 正走向“AI+硬件+操作系统”一体化平台。
✅ Gemini 将成为现实世界的智能层,不再局限于屏幕中。