Gemma 3n (“n”意指 Nano 或 Next-gen)是 Google 推出的最新轻量级开源 AI 模型,旨在实现“设备本地运行(on-device)+ 多模态感知 + 高效率低延迟”三大目标。
它是继 Gemma 3 系列(支持桌面/云端推理)后的首个为移动设备优化的模型架构预览版,同时也构成了下一代 Gemini Nano 系列模型 的技术基础。
- 参数规模:5B 和 8B(分别为50亿和80亿参数)
- 支持模态:文本、图像、音频(语音识别与翻译)、视频(即将开放)

核心亮点功能(兼顾性能、效率与隐私)
✅ 1. 极致轻量与快速响应
- 响应速度提升约 1.5 倍(对比 Gemma 3 4B),在高端 Android 手机上能实现<500ms 的首字延迟。
得益于 DeepMind 创新的 Per-Layer Embeddings(PLE) 技术,内存占用被大幅降低;
虽然模型参数为:
- 5B(50亿) 和 8B(80亿);
实际运行时所需内存仅为:
- ~2GB(5B模型)
- ~3GB(8B模型)
- 这意味着:中端 Android 手机也可运行大模型推理,无需云端支持。
- 适配 Qualcomm、MediaTek、Samsung 等移动硬件平台。
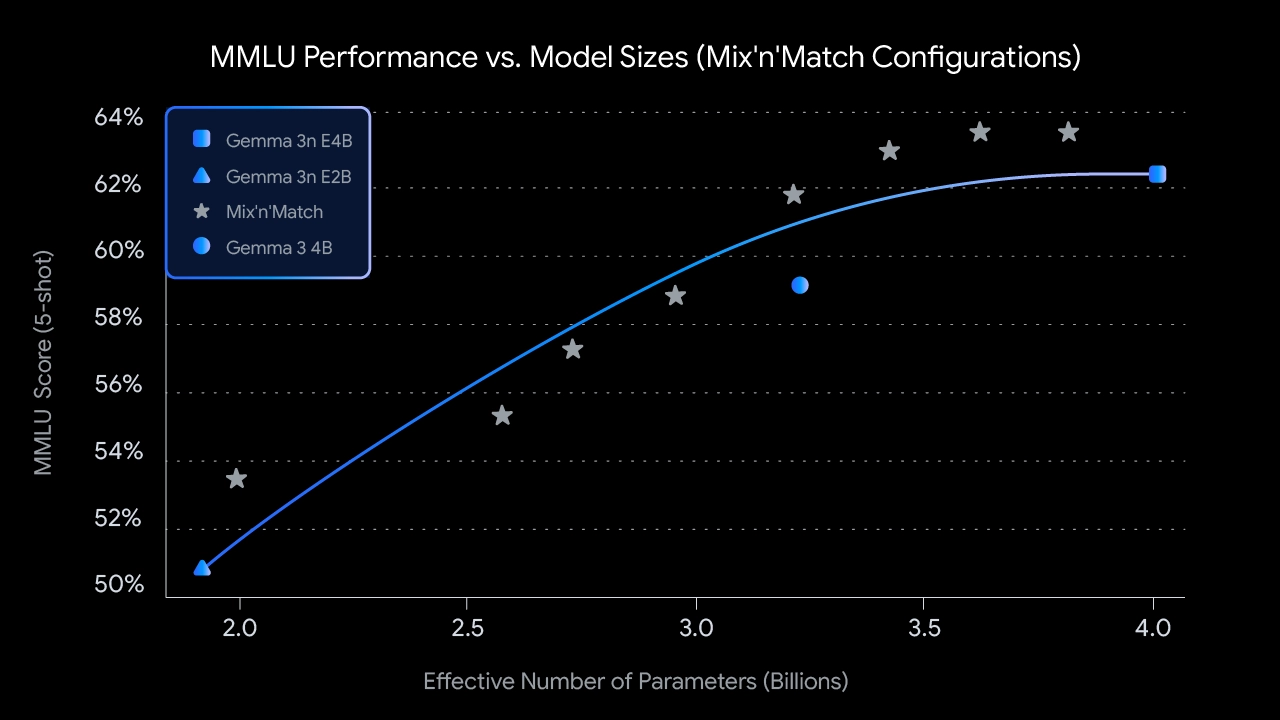
⚙️ 2. 动态可调模型结构(Mix'n'Match 架构)
“Mix’n’Match” 架构让 5B 模型能自动切换成内嵌的 2B 子模型;
- 模型结构内嵌了一个嵌套式子模型(2B 活跃内存模型嵌于 4B 主模型中),开发者可动态调节精度与推理速度,适应不同的使用场景;
- 可根据设备能力或用户需求动态切换精度与速度之间的平衡;
- 这种架构可实现“一个模型覆盖多个场景”
- 能耗控制表现优秀,特别适合电池敏感型设备(手机、眼镜、耳机、边缘设备)。
🛡️ 3. 完全本地运行,隐私优先
- 无需联网即可运行推理任务;
- 所有数据在设备上处理,不上传云端,保障用户隐私;
- 适用于手机、笔记本、边缘设备等。
多模态能力增强
Gemma 3n 是目前 Google 最先进的移动端多模态开源模型之一,其支持范围包括:

模型用途:打造下一代“随身智能体验”
📱 预期应用场景

性能如何
📊自然语言任务
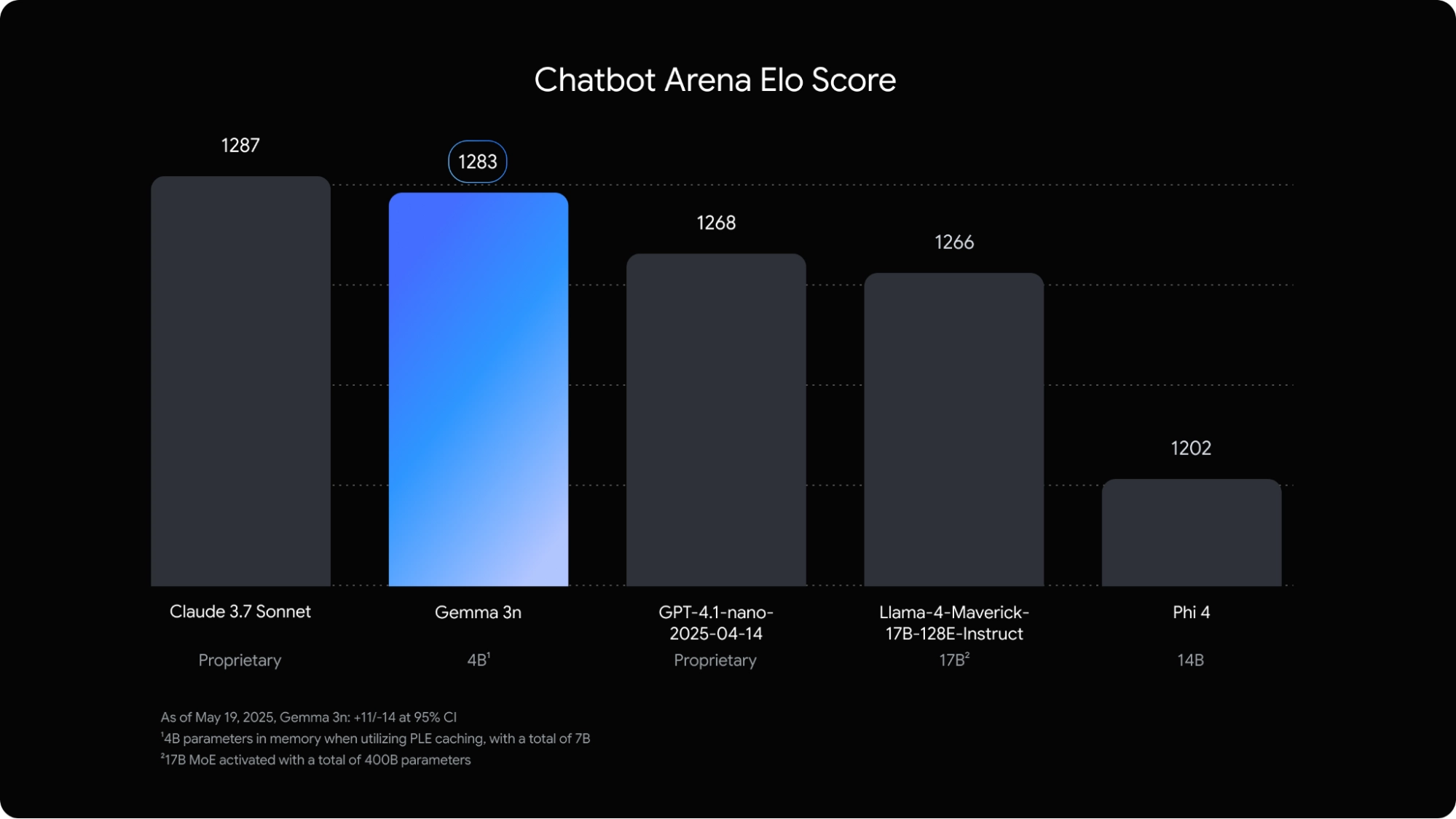
Google 称其模型在 Chatbot Arena 排行中表现“高居前列”,在用户偏好评分中:
- 可媲美主流开源模型如 Mistral 7B、Phi-3、LLaMA 3;
- 在中英双语任务中表现稳定,尤其是在处理多轮对话、长文本生成、逻辑问答方面。
🌐 多语种能力表现:
- 在多语言 benchmark(如 WMT24++, ChrF)中得分 50.1%;
- 在 日语、德语、韩语、法语、西班牙语 等语种任务上表现尤佳;
- 这说明它在国际市场适应性方面优于许多西方主导的模型。
与同类模型对比

核心技术详解
Gemma 3n 的关键技术亮点之一是显著降低运行时内存占用,通过以下三种方式实现:
1️⃣ Per-Layer Embedding(PLE)
- 是什么:一种由 Google DeepMind 提出的新型嵌入策略;
- 作用:每一层使用独立的低维嵌入向量来代替全模型共享 embedding 表;
优势:
- 减少内存复制;
- 更好地压缩表示空间;
- 支持按需加载(lazy loading);
效果:使 5B / 8B 参数模型的动态运行内存分别降低到 约 2GB / 3GB;
- 类似于将大模型“伪装”成一个 2B 或 4B 的轻量级版本运行。
2️⃣ Key-Value Cache Sharing(KVC Sharing)
- 是什么:Transformer 模型在推理时需存储注意力机制的中间结果(Key 和 Value);
- 作用:多个层或步骤共享这部分缓存,减少重复计算和内存冗余;
优势:
- 降低推理内存开销;
- 加快序列生成速度,提升多轮交互体验。
3️⃣ Advanced Activation Quantization(AAQ)
- 是什么:对中间激活值进行量化(例如从 float32 降为 int8 或 int4);
- 作用:大幅降低模型的计算量与内存带宽需求;
优势:
- 保持模型精度的同时减小体积;
- 支持模型在移动芯片(Qualcomm、MediaTek)上高效运行;
- 与 PLE、KVC 联合使用,可进一步压缩至移动设备可接受的水平。
混合架构设计:Mix’n’Match 机制
🧩 “一套模型,多种能力”
Gemma 3n 内部通过 MatFormer 训练策略 实现了一种嵌套子模型机制:
模型结构功能说明主模型(如 4B)具备高精度推理能力子模型(如 2B)性能轻量、响应快速动态切换根据任务复杂度、设备资源自动选择运行路径子模型继承子模型权重由主模型共享,避免重复部署
这种结构具备以下优势:
- 开发者无需部署多个模型版本;
- 可在运行时动态调节质量与延迟之间的权衡(如:导航助手 vs 语义翻译);
- 提高能耗控制能力,适配高低端设备。
怎么使用 Gemma 3n?
Google 已开放两个方式,适合不同人群:
方式一:AI Studio(网页版)
- 不用安装,直接在浏览器中体验模型的文本理解与生成;
- 适合产品经理、开发者预览模型效果。
👉 地址:Google AI Studio(需要 Google 账号)
方式二:Google AI Edge(本地开发工具)
- 适合开发者想把模型集成进 APP、本地系统、硬件设备;
- 提供 SDK、文档、代码示例,支持文本和图像模型部署;
- 支持 Android、Chrome、嵌入式设备等。
详细介绍:
官方介绍:https://developers.googleblog.com/en/introducing-gemma-3n/