Black Forest Labs 推出的新一代多模态图像生成与编辑模型:FLUX.1 Kontext,不同于传统的文生图模型,Kontext 同时理解文本与图像输入,能够实现真正的“上下文生成与编辑”。
传统的 text-to-image(文本生成图像)模型 如 DALL·E、Stable Diffusion 等虽然强大,但也存在很多局限:
- 只能通过文字控制,无法灵活结合图片作为上下文;
- 无法连续编辑或保留角色特征,缺乏“认知连续性”;
- 局部编辑需要复杂遮罩或 finetuning;
- 多轮操作后常常图像退化(失真、风格丢失);
- 编辑速度慢,无法满足实时交互需求。
🔍 FLUX.1 Kontext 的目标:
构建一个真正 “上下文感知”(context-aware) 的图像生成与编辑引擎。
也就是说:
你可以像 Photoshop + GPT 一样自然地用“图+文”控制图像生成与修改,灵活、高效,并保持人物、风格一致性。
它主打:
- 图像上下文理解能力(不仅能从文本生成图像,还能理解图像并进行修改)
- 快速交互式编辑能力(低延迟、逐步迭代)
- 角色一致性、局部编辑、风格迁移等能力

Kontext 有哪些亮点?
- 角色一致性:可在多个场景中保持人物或元素的一致性
- 局部编辑:只编辑图像的特定部分,不影响其他区域
- 风格参考:可在指定风格下生成新场景
- 交互速度快:快速迭代、延迟极低
模型版本:

- FLUX.1 Kontext [pro]
适合快速迭代编辑
支持连续编辑,保持角色、身份、风格和特征在多个场景中的一致性 - FLUX.1 Kontext [max]
高性能版本,具备更强的提示词遵循能力、更出色的排版表现与一致性 - FLUX.1 Kontext [dev]
我们最先进的图像编辑模型的开源权重版本
目前处于私测阶段(private beta)
主要功能
📌 1. 图文混合控制(Text + Image Prompt)
不仅可以用文字生成图像,也可以上传图像、再用文字修改它。
📎 举例:
- 上传一张人物照片,输入:“让她微笑并看向镜头” → 模型只改变表情与头部朝向,保留其他细节。
- 输入:“将她T恤上的文字换成‘Context Matters’” → 模型准确局部替换图中文字。
输入:“把背景换成夜店风格” → 模型替换背景,保留角色样貌、穿着、动作等。

🎯 2. 局部编辑(Local Editing)
- 可以精确修改图像中的某个部分,而不影响整体风格或其它区域。
- 不需要做遮罩、分层或图像标注。
🧠 这意味着:你可以像修图师一样,只“动你想动的地方”。

左图: 输入图像; 中图 :根据输入编辑:“将‘YOU HAD ME AT BEER’改为‘YOU HAD ME AT CONTEXT’”, 右图: “将场景改为夜总会”
👥 3. 人物与风格一致性(Character & Style Consistency)
- 无论你生成几个不同场景的图像,只要提供相同的参考图或描述,模型能自动保持人物的面孔、表情、姿态一致。
- 对风格(如动漫、写实、水彩)也能保持统一表达。
🧠 用于构建连续的视觉内容(如漫画角色、虚拟代言人)非常有价值。

🔄 4. 多轮连续编辑(Iterative Editing)
- 可以对同一张图反复添加修改:“先让她笑 → 再加墨镜 → 再换背景 → 再改衣服文字”
- 每一步的变化都在保留前一轮基础上进行。
💡这是首次允许多轮自然语言驱动视觉修改的模型体系。

左图: 输入图像; 中图 :根据输入编辑:“将她的头朝向镜头倾斜”, 右图: “让她笑”
⚡ 5. 速度快、交互性强(Low Latency Inference)
- 推理速度高达当前主流模型的 8 倍;
- 在编辑、生成过程中可实现近乎“实时反馈”,适合用户快速试错与调整。
评估效果如何?表现是否领先?
Black Forest Labs 提出了一个新的测试集:KontextBench,用于衡量上下文驱动图像任务的模型能力。
FLUX.1 模型在以下六个维度均有领先表现:
- 文本引导编辑的准确性
- 图像保真度与风格一致性
- 角色形象在多个画面中保持不变
- 图文排版与内容适配
- 多轮编辑中的稳定性
- 响应速度与推理效率
结果显示:
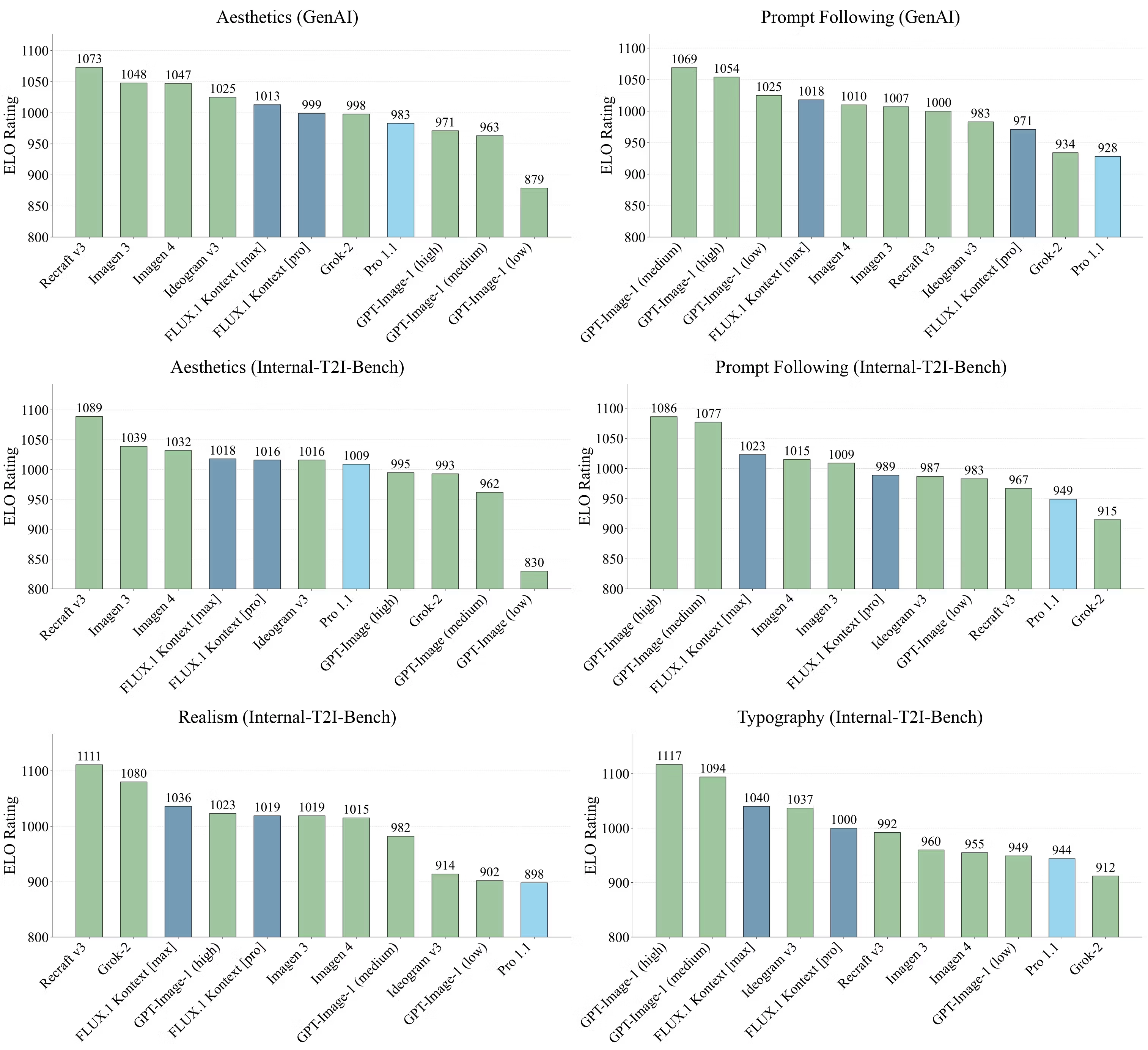
✅ FLUX.1 Kontext [pro] 在“角色一致性”和“文本编辑精度”两个核心任务上是当前表现最好的模型之一。
他们还推出了一个交互界面
💻 FLUX Playground 简介:
一个为开发者、创意者准备的 图形化界面平台,无需任何代码或集成,即可快速使用 FLUX 模型。
✅ 特点:
- 输入文本或上传图像,实时体验生成与修改效果;
- 可进行多轮编辑,查看每一步的对比;
- 用于向客户或决策方展示原型与能力演示;
🔗 地址: https://playground.bfl.ai/
当前的限制与注意事项
BFL 也诚实地列出了当前的模型限制:
- 多次连续修改后,图像可能出现质量下降(如颜色伪影、细节模糊);
- 个别情况下,模型对文本理解会偏离或忽略某些要求;
- 对“世界知识”的理解较弱(例如可能画出结构不合理的场景);
- 模型压缩蒸馏过程中可能会损失部分细节(影响高保真度应用)。
这说明它更适合图像创意、概念图、产品原型、场景图等需求,而非最终成图精修阶段。