OpenAudio 宣布发布最新的语音生成模型 —— S1 模型,目标是达到专业配音演员的表现力与自然度。该模型由 Hanabi AI 旗下研究实验室开发,并通过产品平台 Fish Audio 对外发布。
S1具备:
- 高度自然、流畅的声音
- 丰富的语气和情绪控制
- 强大的指令跟随能力(instruction following)
其训练数据超过 200 万小时音频,模型参数高达 40 亿(S1),是一款标志性里程碑产品。
模型版本

两者都支持情绪、语气标签、拟声控制等全部功能,差异主要在于质量与性能权衡。
主要功能特点
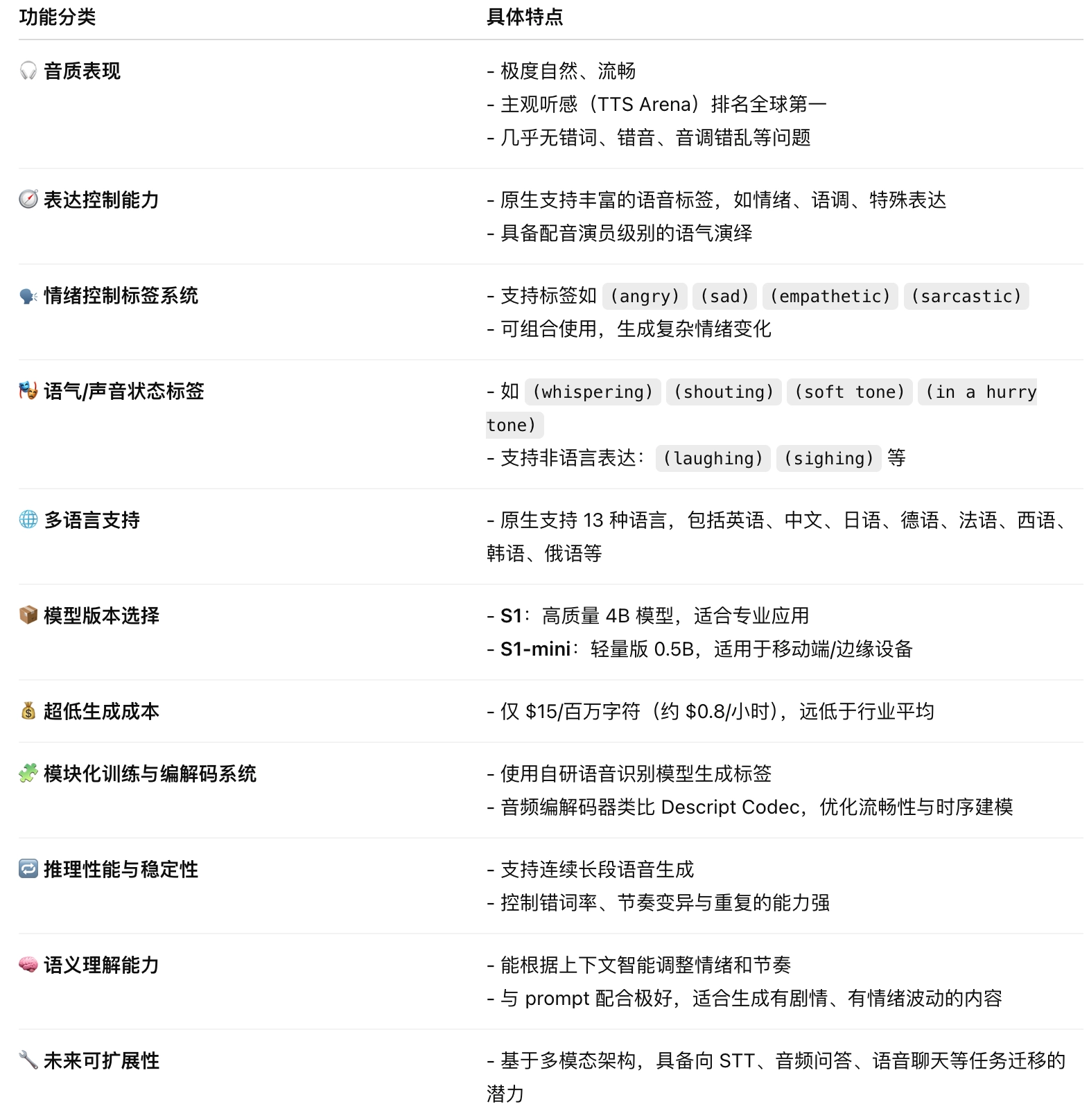
最大亮点:像配音演员一样“演”
S1 的最大创新,是它能理解并演绎“说话人的情绪与语气”,就像专业配音演员一样。
🗣️ 它是怎么做到的?
OpenAudio 首先训练了一个自研的 语音识别模型(STT),能自动识别语音中的:
- 情绪(如:悲伤、愤怒、欣喜、同理、讽刺等)
- 语气(如:急促、轻声、喊叫、尖叫等)
- 说话人角色信息
然后,用这些“语音标签”标注了 超过 10 万小时语音数据,作为 S1 的训练输入。
🧩 支持的语音控制标签:
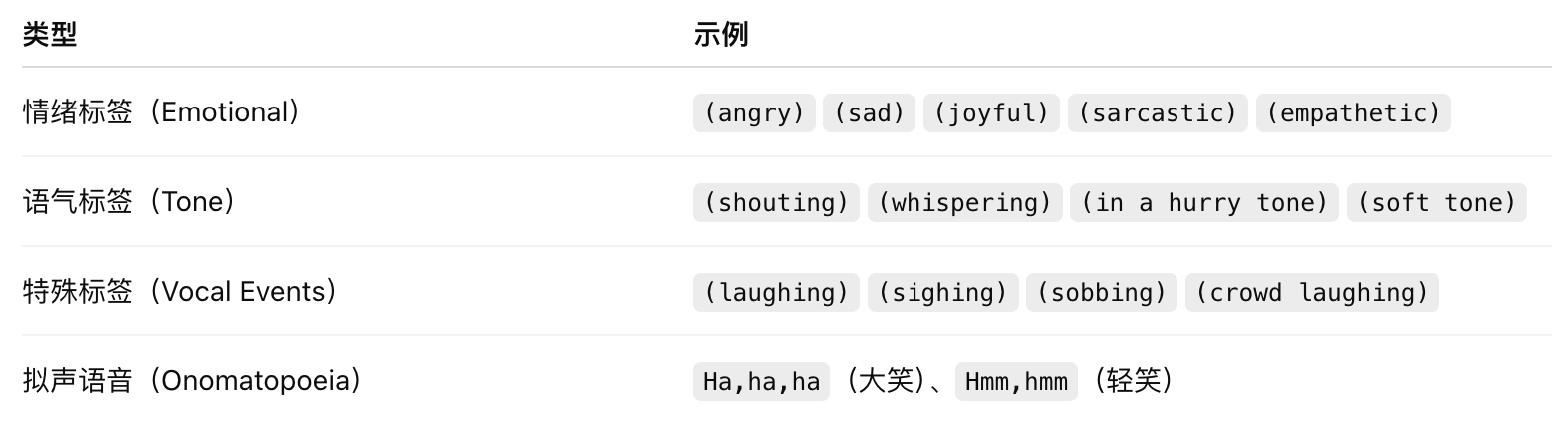
S1 最突出的能力是其丰富的语音表达控制标签系统,包括:
🎭 1. 情感标签(Emotion Markers):
如 (angry) (sad) (joyful) (sarcastic) (empathetic) 等
🎤 2. 语调/语气标签(Tone Markers):
如 (in a hurry tone) (whispering) (shouting) (soft tone)
💬 3. 特殊标签(Special Markers):
(laughing) (sighing) (sobbing) (crowd laughing) 等人类非语言行为
支持拟声词标记:如 Ha,ha,ha(笑声)Hmm,hmm(轻笑)
这些功能来自 OpenAudio 自研的 情感语音识别 STT 模型,可自动标注音频中说话者、情感、语气等信息,进一步提升 TTS 指令理解与还原能力。
这些标签可以插入文本中,引导 AI 合成具有表现力的语音。例如:
(speaker 1) (concerned) Honey, what's wrong?
(speaker 2) (pretend to be tough) Nothing. I just said goodbye to Sanjay.
原生多语言支持(全球化)
S1 提供原生支持以下语言,确保全球应用的语音输出一致性:
- 英语、中文、日语、德语、法语、西班牙语
- 韩语、阿拉伯语、俄语、荷兰语、意大利语、波兰语、葡萄牙语
如何实现高质量?
S1 的高性能来自以下关键设计:
📦 数据与训练策略:
- 200 万小时音频数据(业界最大规模之一)
- 自研 奖励模型(reward model) 用于优化表现力
- 在线强化学习 RLHF(使用 GRPO 算法):用于模型微调,增强语音真实性与听感质量
🧱模型结构与推理优化
- 架构:基于 Qwen3 多模态架构,支持未来扩展为音频问答、文本问答、语音识别等任务(目前仅开放 TTS 功能)
- 音频编解码:自研类 Descript Audio Codec 系统 + Transformer 结构
- 优化技术:使用在线 RLHF 强化学习(基于 GRPO 策略)优化语音表现力
📊 多项指标全球领先:

- HuggingFace TTS-Arena-V2 排名第 1(人类主观评分)
- Word Error Rate(词错误率):0.008,远优于业界模型
- Character Error Rate(字错误率):0.004
- 极低的伪音、错词、语调失真等常见 TTS 问题
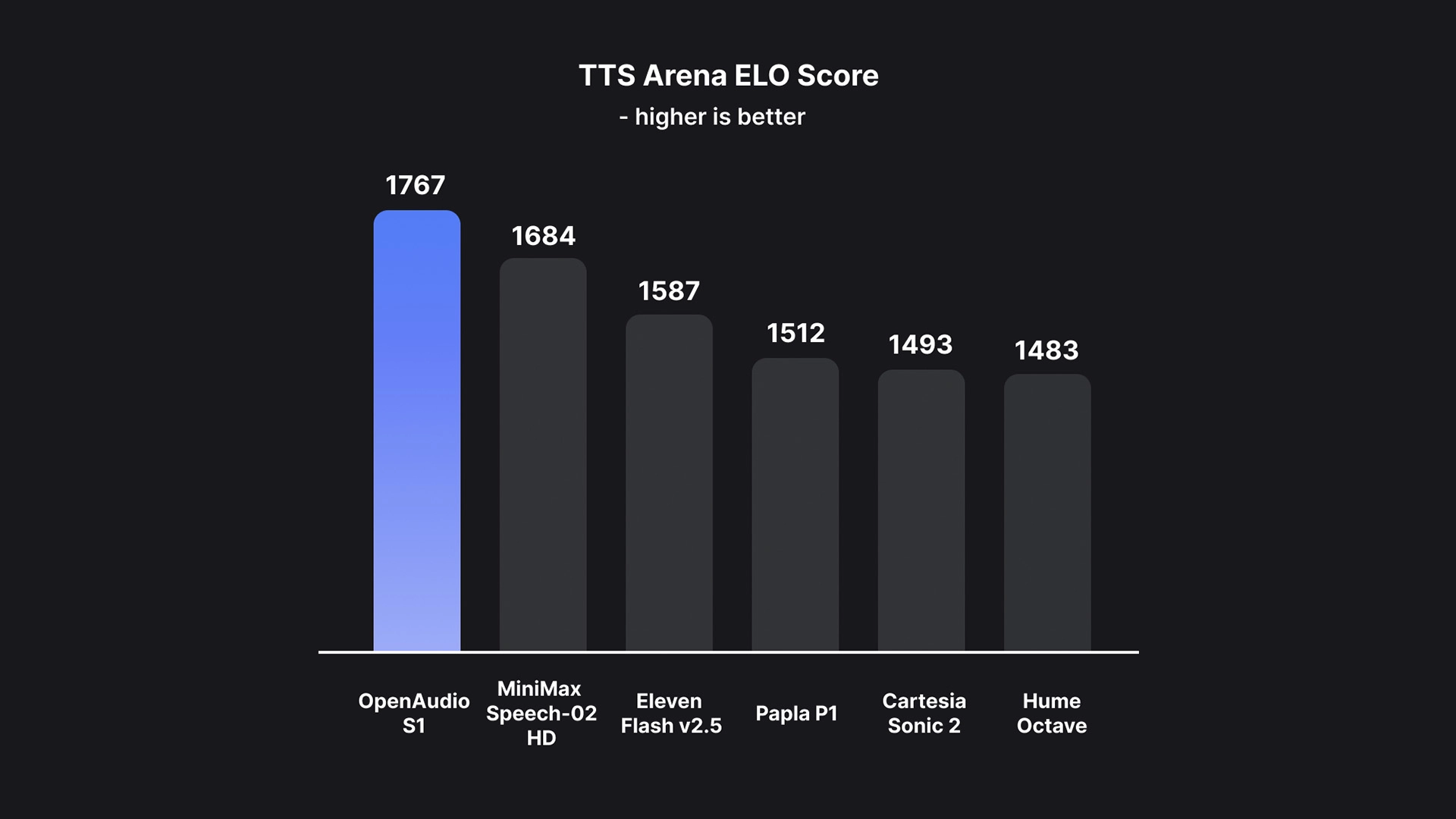
S1 甚至在语音表达、语音清晰度、语者一致性等方面全面超越现有模型。
价格极低,人人可用
S1 是当前市场上最具性价比的高质量 TTS 模型:
- 仅 $15/百万字节
- 相当于大约 $0.8/小时 音频成本
- 明显低于市场主流(如 ElevenLabs、PlayHT 等)
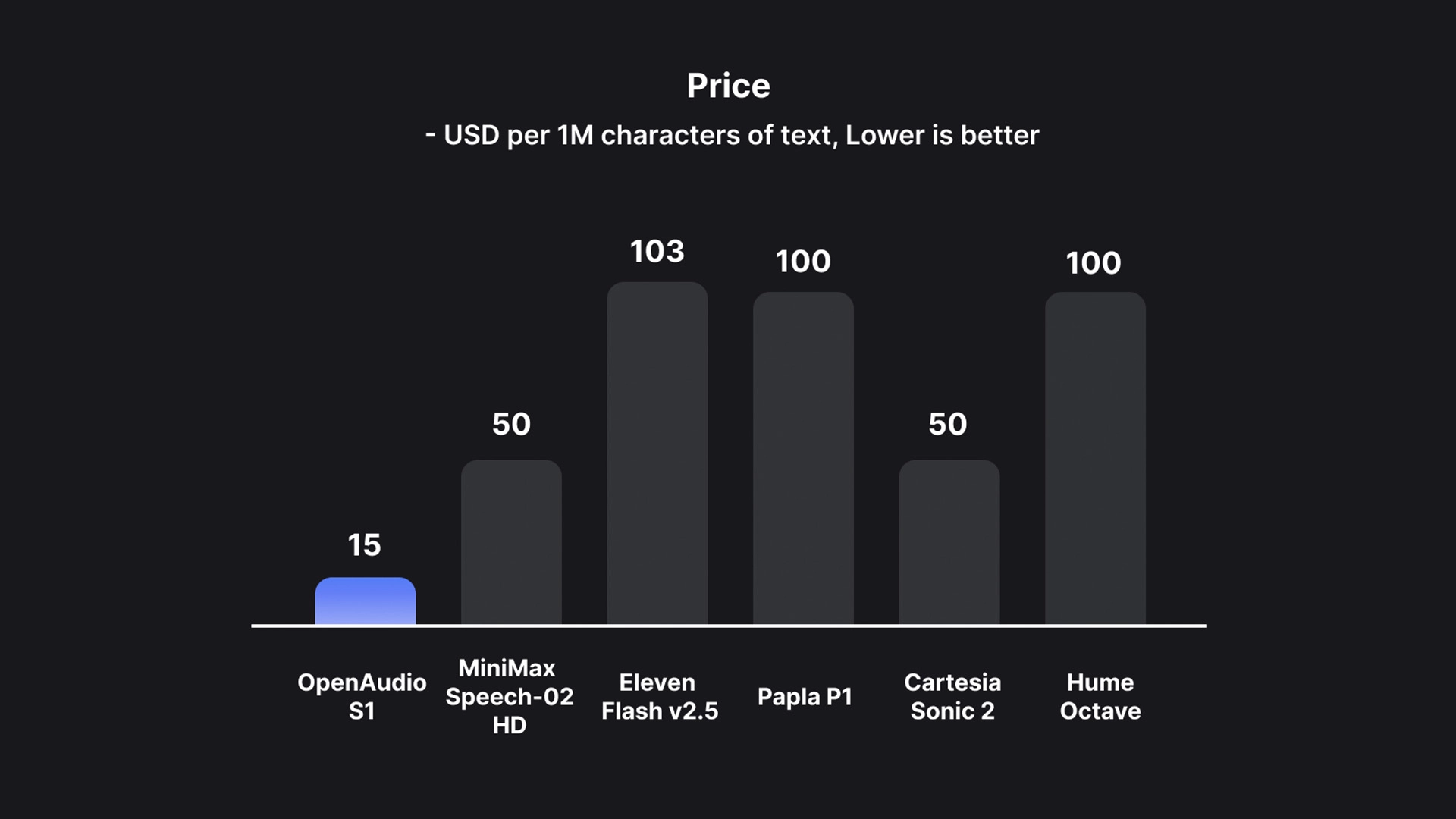
开发者可以用非常低的成本部署大规模语音应用,包括客服机器人、播客生成、AI 角色配音等。
如何体验?
你可以通过 OpenAudio 的语音平台 Fish Audio Playground 在线体验该模型的语音效果(目前仅开放 TTS 功能,未来将支持 STT、TextQA、AudioQA 等)。
在 Fish Audio Playground 上体验