MiniMax 发布 MiniMax-M1,全球首个开源的大规模混合注意力推理语言模型。其主要特点是融合了 混合专家架构(MoE) 和高效的 Lightning Attention 机制,在推理速度、长文本处理和复杂任务表现方面具有显著优势。
在多数任务上,MiniMax-M1 显著优于其他开源大模型(如 Qwen3、DeepSeek-R1),并逼近甚至在部分维度超越商用闭源模型。
该模型基于前代模型 MiniMax-Text-01 开发,总参数规模为 4560亿,每个token激活参数为 45.9亿,支持最长 100万tokens 的上下文输入(约为 DeepSeek R1 的8倍)。

模型版本
MiniMax-M1-40K: 上下文:100万 推理预算:tokens40K
MiniMax-M1-80K: 上下文:100万 推理预算:tokens80K
混合专家模型(Mixture-of-Experts, MoE)
- 每个 token 激活约 45.9 亿参数(总参数为 4560 亿),仅调用部分专家,提高推理效率。
- 平衡了“大模型能力”与“可落地部署”的矛盾。
Lightning Attention 机制
- 一种专为大规模上下文优化的注意力方式。
- 相比 DeepSeek R1 等模型,在处理 10 万 tokens 的生成任务时,MiniMax-M1 的计算量仅为其 25%。
超长上下文处理
- 原生支持 100 万 token 的上下文,远超绝大多数同类模型(例如 DeepSeek R1 支持 128K)。
训练成本
- RL 强化训练只需 3 周 + 512 H800 GPU
- 总成本仅为 53.5 万美元
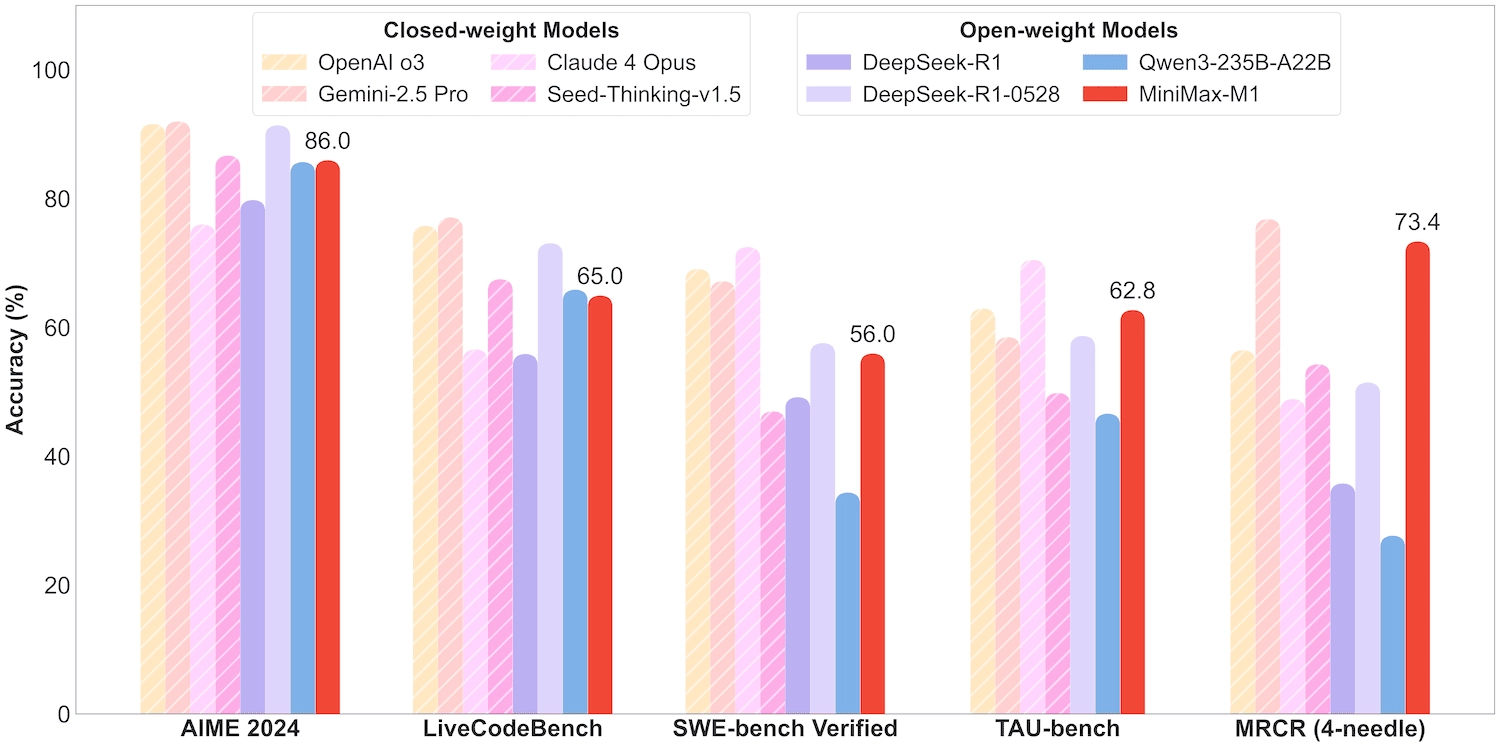
MiniMax-M1 能力表现
✅ 1. 数学与逻辑推理
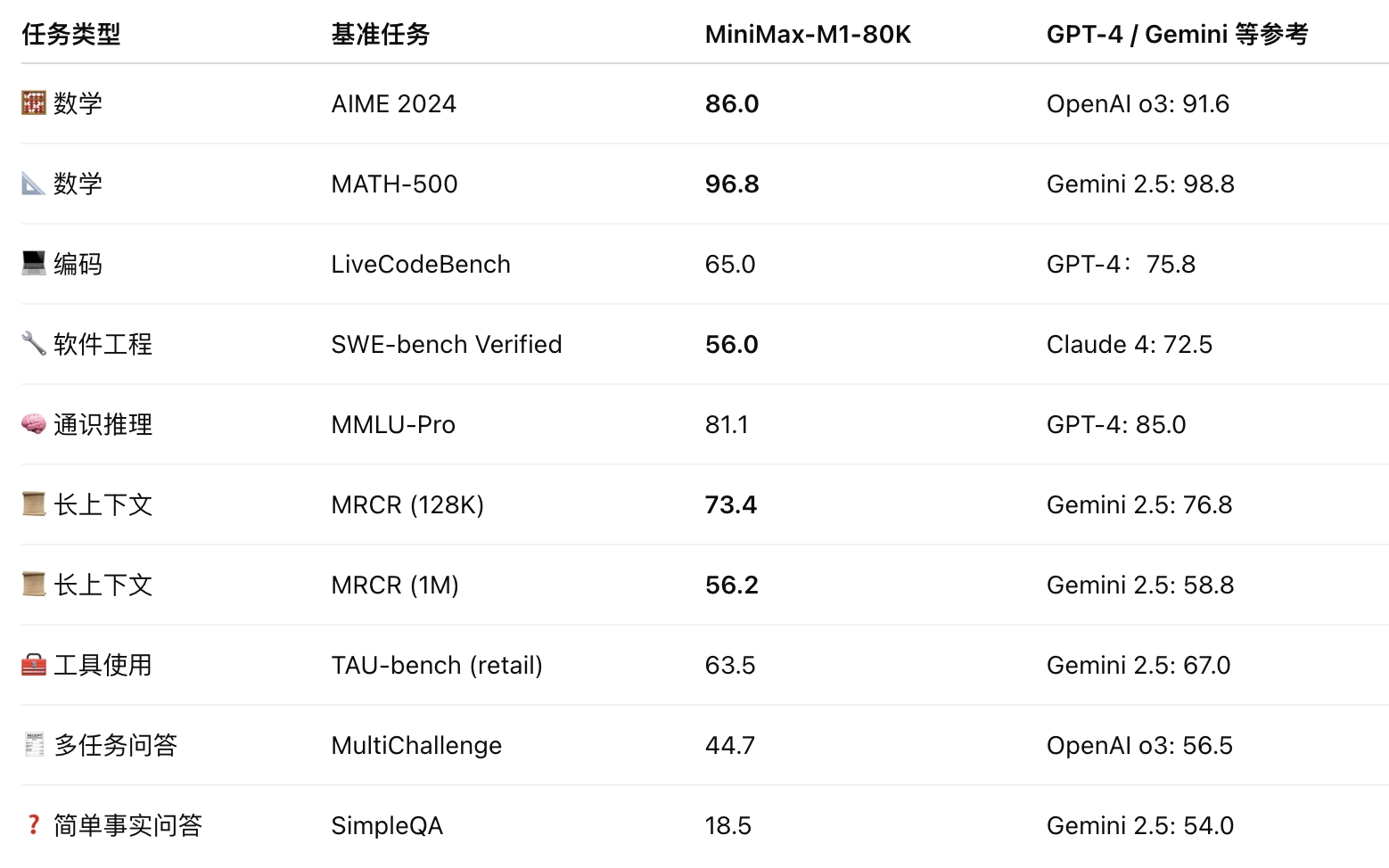
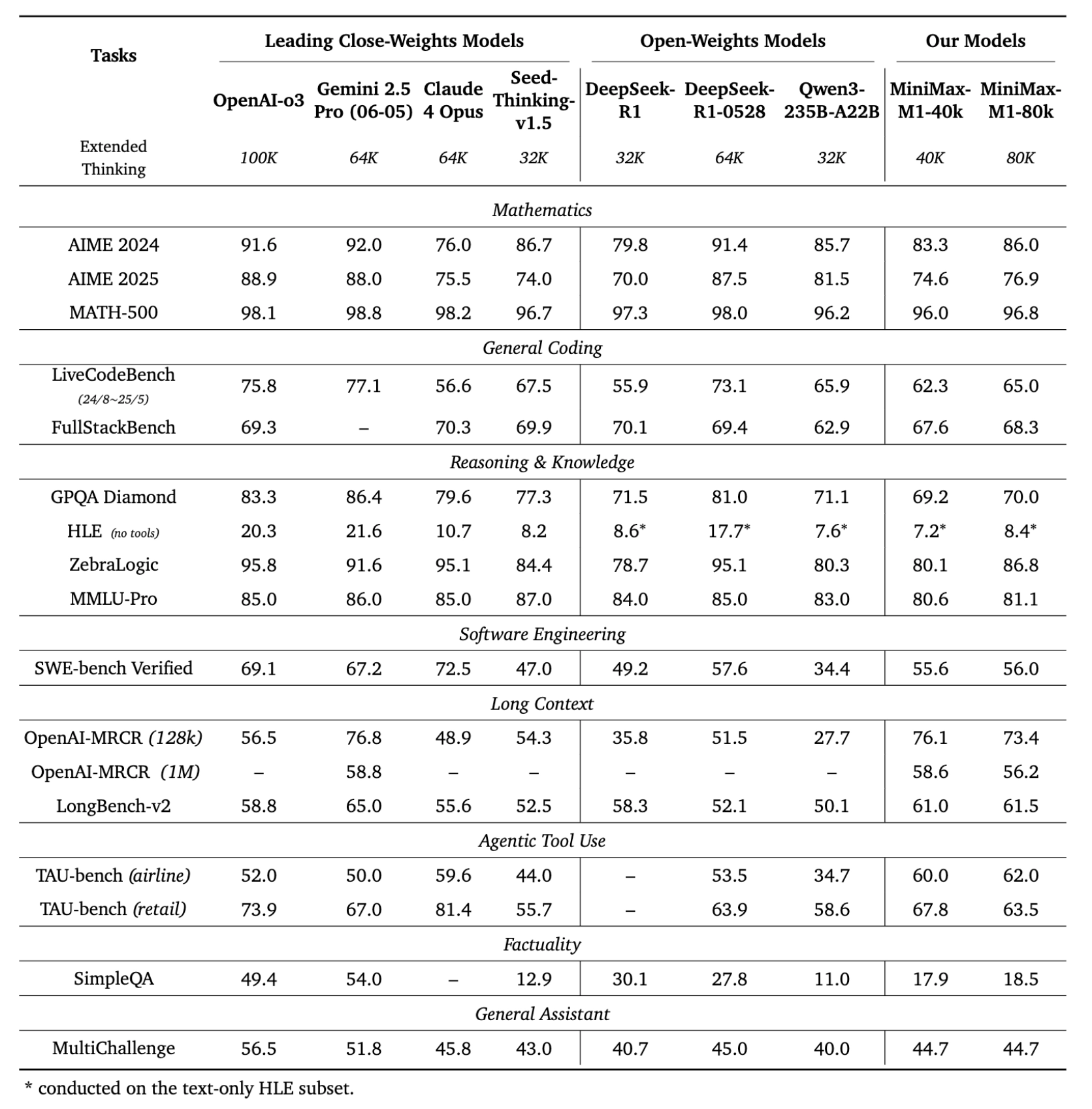
- 在 AIME 2024 竞赛题中得分高达 86.0%
- 在 MATH-500 达到近乎满分(96.8%)
- 显示出优秀的链式思考(Chain-of-Thought)能力
- SFT + RL 阶段针对性强化了反思式推理路径
✅ 2. 通用与高级编程任务
- 覆盖从算法编程题(LiveCodeBench)到多模块工程任务(FullStackBench)
- 展现出对代码语法、逻辑结构的全面理解
- 表现稳定,适合用于代码生成或智能IDE集成
✅ 3. 真实软件工程任务
- SWE-bench:基于真实 GitHub 问题,验证模型是否能自动完成 bug 修复与 PR 提交
- MiniMax-M1 构建了真实沙盒系统,并在代码执行层面进行验证
- 得分 56%,强于所有开源模型,仅次于最新闭源模型
✅ 4. 超长文本能力
- 支持 100万 tokens 上下文(原生支持)
在 MRCR、LongBench 等任务上表现出色:
- MRCR-128K 得分 73.4%:比 GPT-4 更接近真实理解
- 能处理复杂指令、法律文书、科研文档等长内容
✅ 5. Agent 能力:工具使用与调用
- TAU-bench 模拟真实 API 使用场景
MiniMax-M1 超越 Gemini 2.5 和 Claude 4:
- Airline:62%
- Retail:63.5%
- 表明其在复杂推理+动作调用的智能体任务中具备强大适应能力
✅ 6. 对话与助手能力
- MultiChallenge 得分 44.7%
- 与 Claude 4、DeepSeek-R1 持平
- 在多轮任务型对话中表现稳定,适合作为助理底座模型
⚠️ 7. 劣势:事实问答能力较弱
在 SimpleQA 上表现为 18.5%,说明:
- 对短、明确问题的回答准确性还有提升空间
- 与训练数据分布或奖励模型偏好有关
MiniMax-M1 的技术创新与亮点
🔧 架构创新:混合注意力机制(Hybrid Attention)
🔹 1. Lightning Attention + Softmax Attention
- Lightning Attention 是一种 线性复杂度注意力机制,替代传统 quadratic attention,计算量随着文本长度增长更慢。
- 每 7 层 Lightning Attention 插入 1 层 Softmax Attention,用于强化上下文建模能力。
优势:
- 支持长达 1,000,000 tokens 的上下文输入
- 大幅减少推理计算量(例如生成 100K tokens 时,FLOPs 仅为 DeepSeek R1 的 25%)
🧠 模型规模与计算效率:Mixture of Experts(MoE)混合专家机制
- 模型总参数达 4560 亿,每次仅激活 45.9 亿(即约 10%)
- 使用了 32个专家模块,每个输入选择部分激活
优势:
- 计算效率高:在不损失能力的前提下,只使用部分参数进行推理,显著降低推理与训练成本
- 可扩展性强:总参数可扩展至千亿级别而不影响使用成本。
- 可微调性好:仅优化局部专家,也利于领域适配。
- 保持大模型的表现力,同时适用于多任务调度
🧪 强化学习训练优化:新RL算法 CISPO
🔹 问题:传统方法如 PPO、GRPO 存在 token 剪枝问题,会忽略推理中的关键转折点(如“等等、再想一下…”)
🔹 解决方案:MiniMax 提出 CISPO(Clipped IS-weight Policy Optimization)
- 改为“剪裁采样权重”,保留所有 tokens 的训练信号
优势:
- 保留罕见但重要的推理路径
- 训练更稳定,效率更高
- 在与 GRPO、DAPO 的对比中训练速度提升 2倍
📈 推理性能全面提升:在多个复杂任务中具优势
- 超长文本处理:支持 1M 输入、80K 输出,适合科研论文、法律文书等场景
- 复杂任务推理:在 AIME 数学、LiveCodeBench 编程、SWE-bench 软件工程任务中表现优异
- 工具调用能力:在 TAU-bench 超越 Gemini 2.5 Pro、Claude 4,适合构建复杂智能体
🧰 工程效率优化
- RL 训练只需 3 周 + 512 H800 GPU
- 总成本仅为 53.5 万美元,大幅低于一般 GPT-4 等闭源模型训练开销
- 推理和训练均具成本优势,有助于模型落地与普及
📦原生 Function Calling + Tool Use 能力
✅ 创新点:
- 内置函数调用(Function Calling)模块,支持输出结构化调用参数。
- 针对 Agent 应用构建了完整的工具调用评测(TAU-bench)
🔍 优势:
- 无需额外微调,模型可识别何时调用工具,生成参数格式;
- 支持构建搜索增强Agent、任务助手、API交互机器人。
GitHub:https://github.com/MiniMax-AI/MiniMax-M1
模型:https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
论文:https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf