Google 正式发布 Gemini 2.5 Flash 和 Pro 模型,现在任何开发者都可以使用这两个模型来构建、扩展可投入生产的 AI 应用。
同时推出新模型 Gemini 2.5 Flash-Lite (预览版):
- 这是 Gemini 2.5 系列中响应最快、成本最低的模型。
- 特别适用于需要低延迟和高效率响应的实际应用场景。
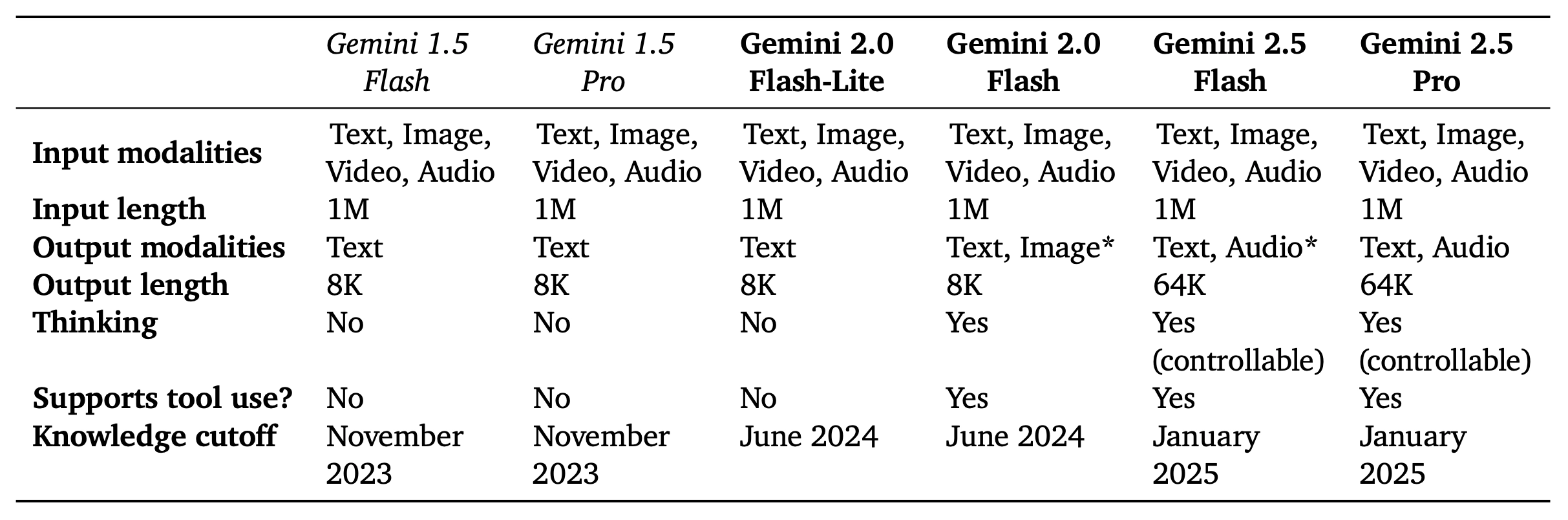
🧬 三款模型对比概览

🔍 Gemini 2.5 Flash-Lite 的详细特点
✅ 1. 成本效率最高,速度最快
- 相较Pro模型,其推理速度更快,成本更低。
- 比 2.0 Flash-Lite 和 2.0 Flash 延迟更低,推理速度更快;
- 每次调用的成本显著降低,适合部署在大规模系统或用户场景中。如 AI客服、搜索摘要生成、多轮对话等。
- 为 边缘设备、移动终端、微服务系统 提供轻量解决方案。
✅ 2. 在基础任务上的质量提升
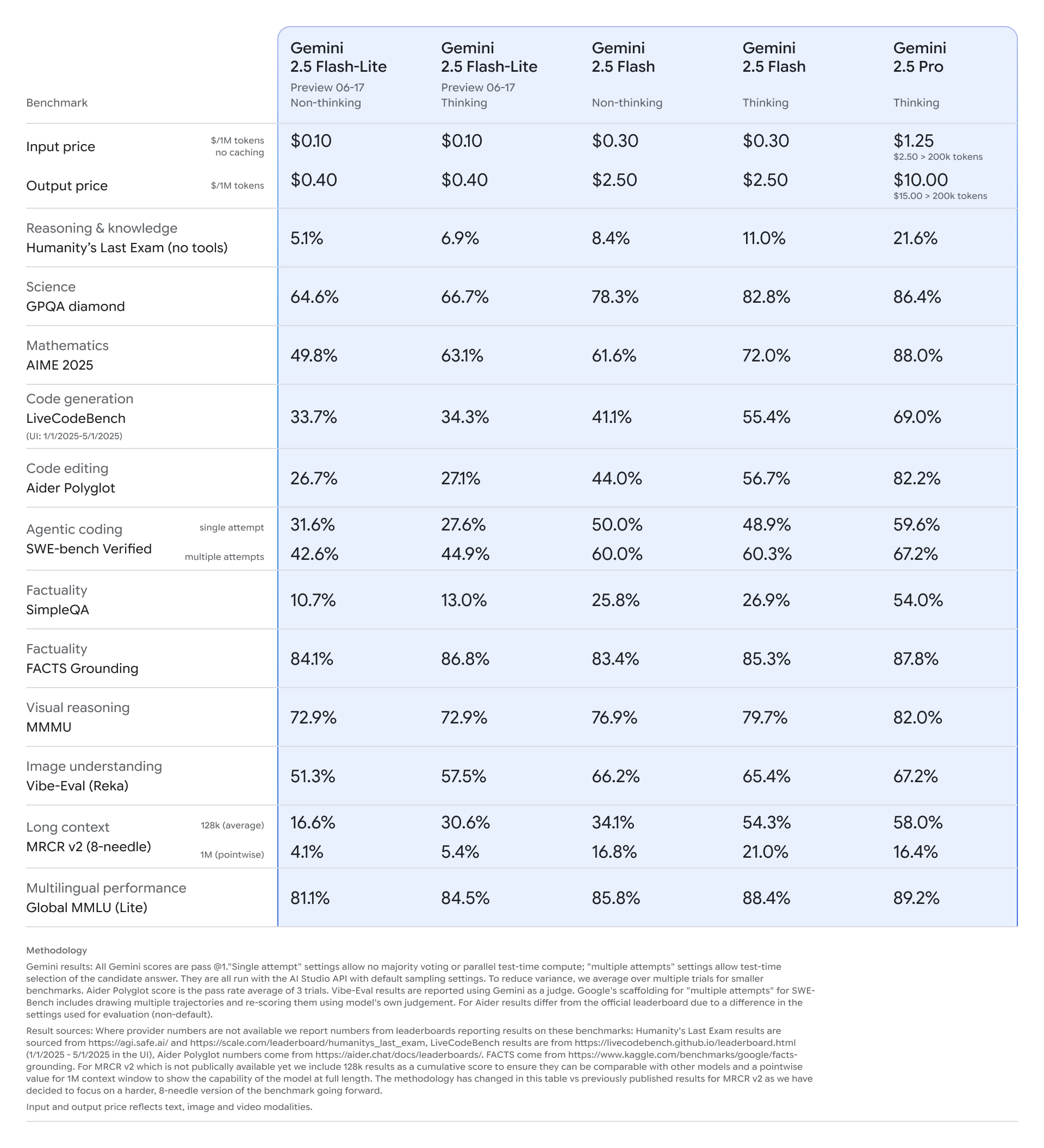
Flash-Lite 在多个标准测试上超过了旧版:
- 代码生成
- 数学/逻辑推理
- 科学理解任务
- 文本/图像多模态输入解析
相比于 2.0 Flash-Lite,其表现更均衡、更全面。
✅ 3. 支持 Gemini 2.5 全功能能力
包括:
- 可控思考机制(Controllable Thinking)
Gemini 2.5 Flash 是首批支持 “思考预算” 的模型之一:
- 用户可以设置推理的计算预算(如Token数),在响应速度与准确性之间灵活权衡。
- 模型在处理复杂任务(如数学题、代码生成)时可使用更多前向传递步骤以提升准确率。
- 多模态处理
尽管不是Pro版,但它依然具备完整的原生多模态支持:
- 输入类型包括:文本、图像、音频、视频。
- 能处理 小时级视频内容、结构化图像(如图表、UI界面)与语音。
- 支持从视频中提取事件、识别场景、生成应用或摘要等任务。
- 工具使用能力(Tool-use):如调用 Google 搜索、代码运行等操作,并拥有 百万 token 的上下文窗口,与 Gemini 2.5 Flash 和 Pro 同等级别。
✅ 4. 性能比较:
- 与旧版 2.0 Flash-Lite 和 Flash 相比,2.5 Flash-Lite 在响应速度、推理质量上全面领先。
- 在编码、数学、科学、推理和多模态等基准测试中均取得更高分数。
延迟更低、成本更低,是目前最具性价比的模型之一。
「谁家AI模型最划算」
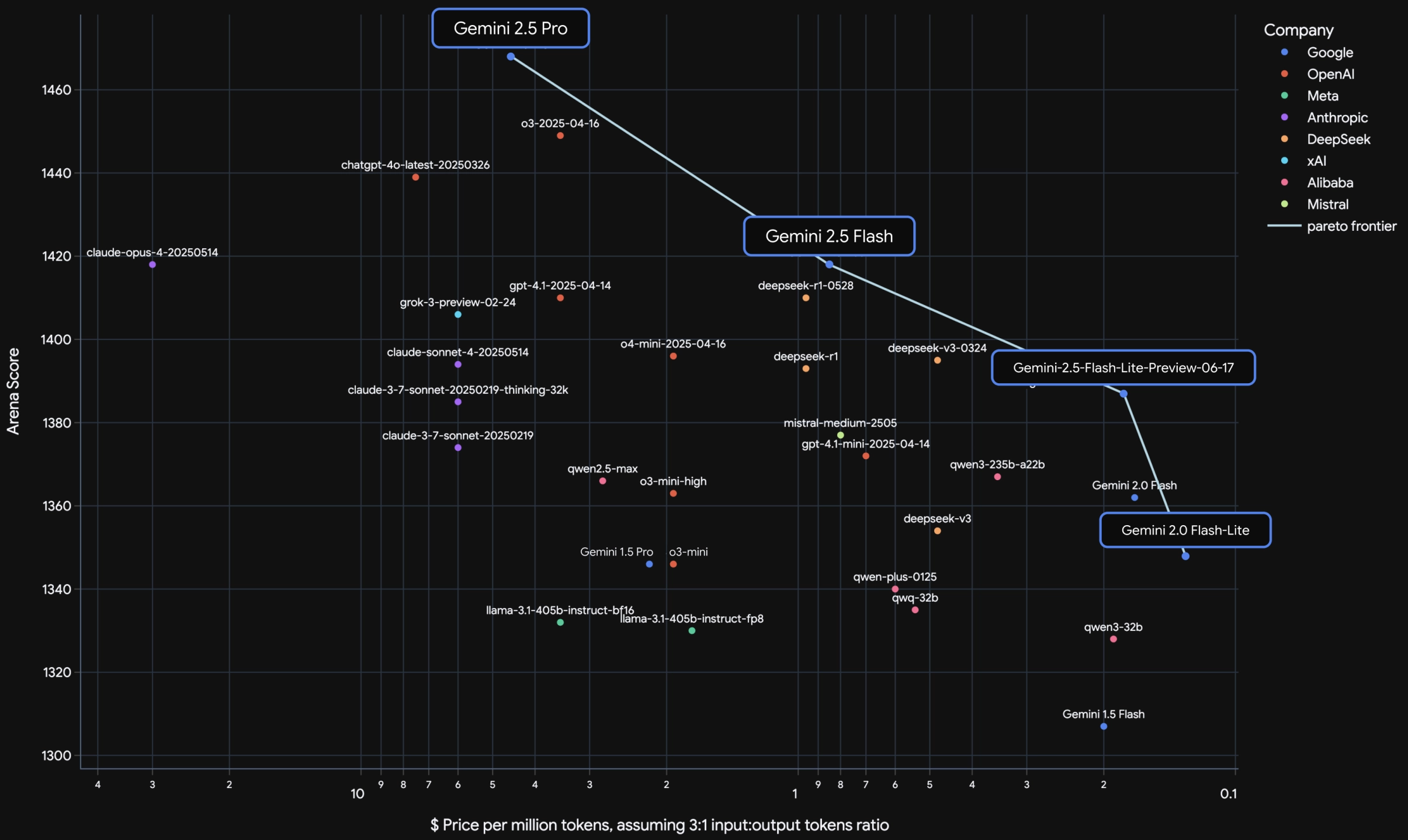
- Gemini 2.5 系列显著提升了性价比上限,将帕累托前沿整体推向右上角。
- Flash-Lite 是目前“最划算的模型之一”,尤其适合预算敏感但仍需强模型能力的应用。
- “思考能力(Thinking)+长上下文+多模态” 是Google Gemini系列能力领先的根本。
📊 怎么看这张图?
- 纵轴(越高越好):模型有多聪明、能干,比如理解能力、写代码、看视频等表现。
- 横轴(越右越便宜):用这个AI模型一次得花多少钱(处理100万个单词的成本)。
✅ 左上角:聪明但贵
✅ 右上角:聪明又便宜!👉这就是最好的组合
图上那条蓝色曲线就是:
📈 “目前世界上最划算的模型”连成的一条线,也叫“最优前沿(Pareto Frontier)”。
🟦 Gemini 2.5 Pro
- Google家目前最强的AI大脑,聪明到爆表。
- 比如能看3小时视频、会写网页应用、能一口气读《哈利波特全集》。
- 缺点是:贵!适合科研、重度开发用。
🟦 Gemini 2.5 Flash
- 小一点的模型,聪明程度跟GPT-4o差不多,但更便宜。
- 平衡好:又快、又便宜、又能思考,适合做聊天机器人、客服、搜索问答系统。
🟦 Gemini 2.5 Flash-Lite(新发布!)
- 超高性价比的“快刀小AI”:成本特别低,但还是挺聪明!
- 比如你有成千上万的客户要同时用AI回答问题,它就非常适合。
- 是图中“右上角”的代表:越右越便宜,越上越聪明,刚好处在最优点上。
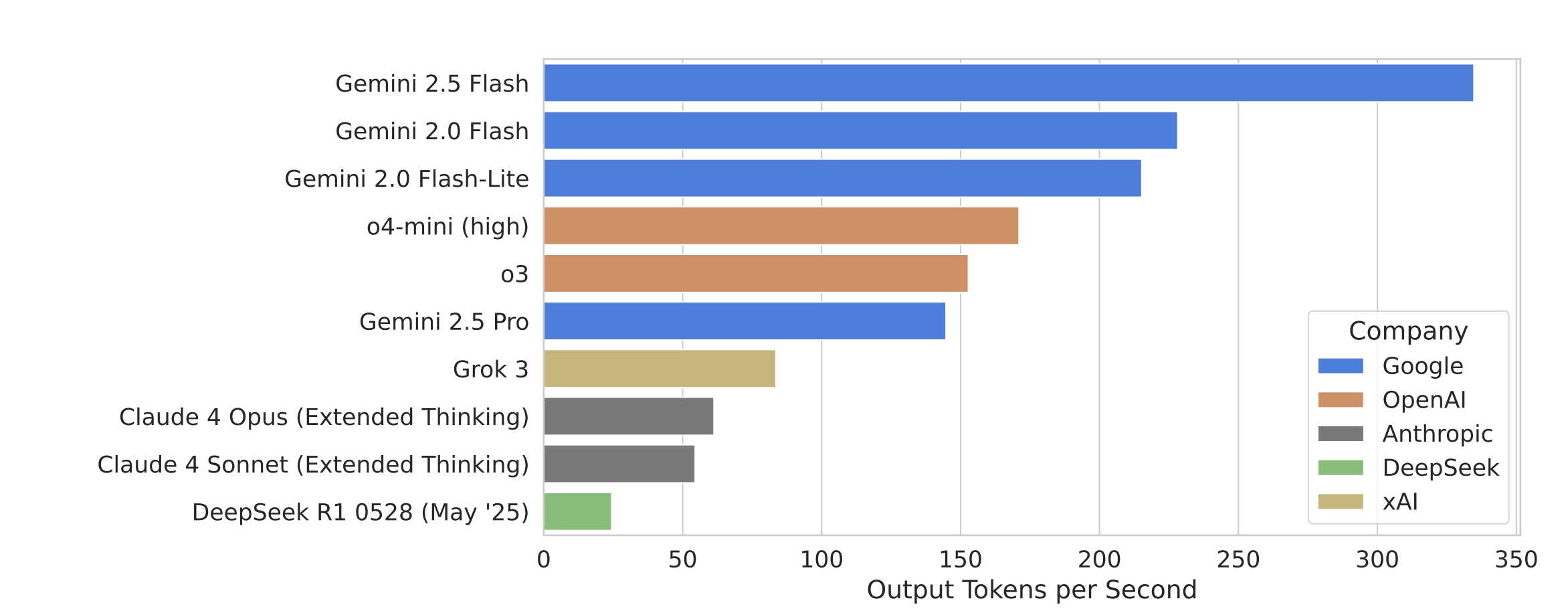
这张图显示的是:
各家 AI 模型 “输出速度” 的对比——也就是生成文字的速度有多快

应用案例演示:
- 一个研究原型:用户上传大型 PDF 文件后,Flash-Lite 模型可实时将其转换为交互式 Web 应用,便于理解和总结复杂内容。
- 示例强调了模型在处理复杂结构化信息方面的强大能力。
如何使用:
所有 2.5 Flash 和 Pro 模型可在以下平台使用:
- Google AI Studio
- Google Cloud Vertex AI
- 适合企业和研究人员快速部署 AI 工具和服务。
技术报告:https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf