我用 Claude Code 花 2 小时没写一行代码做了一个翻译智能体,并且开源了整个过程
这周没怎么更新内容,主要是忙于研究 AI Agent,深度体验了 Claude Code,并且模仿着它的原理实现了一个简单的翻译智能体,最终成品效果不错,只要你输入一段要翻译的文字、或者网址、或者本地文件路径,它就能帮你提取要翻译的内容并翻译。
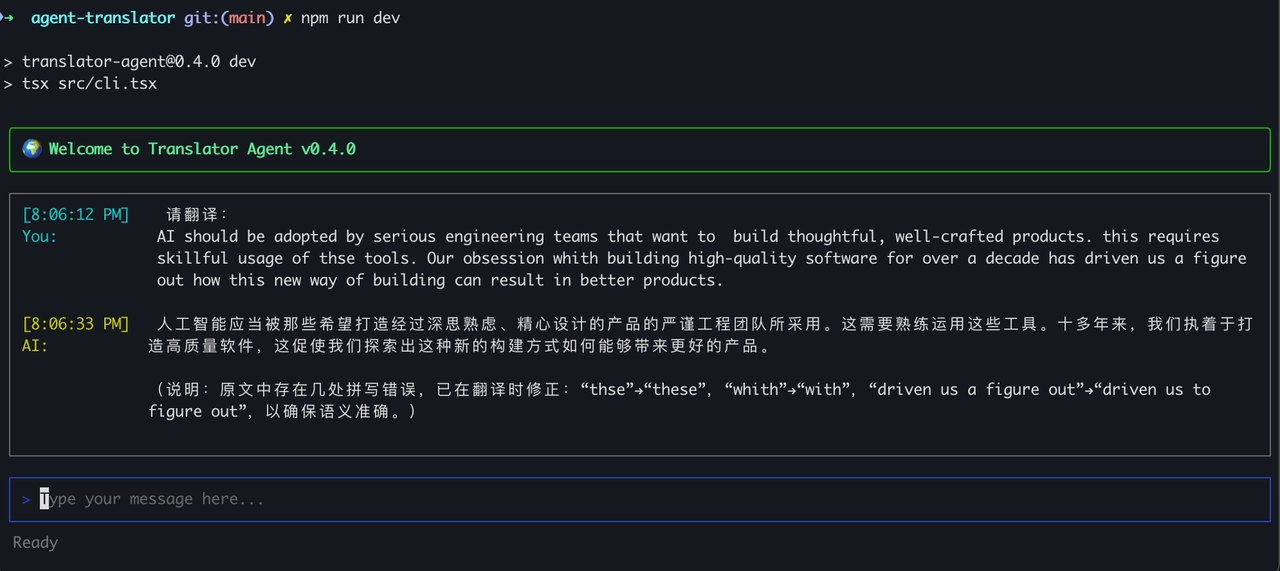 可能你会觉得这似乎没什么了不起的,跟传统的聊天应用也没什么区别,但麻雀虽小五脏俱全,它却是一个真正的 AI Agent。
可能你会觉得这似乎没什么了不起的,跟传统的聊天应用也没什么区别,但麻雀虽小五脏俱全,它却是一个真正的 AI Agent。
那么 AI Agent 和普通 AI 聊天工具有什么区别呢?
关于 AI Agent,我觉得写的最好的文章是 Anthropic 的《构建高效 Agenthttps://baoyu.io/translations/building-effective-agents》,它把Agent 定义的很清楚:
智能体(Agent)这个词可以有几种不同的定义。部分用户认为智能体是完全自主的系统,能够在长时间内独立运作,通过使用各种工具来完成复杂任务。另一部分用户则将智能体定义为更具指令性的实现方式,即严格按照预先设计的工作流程运行的系统。 在Anthropic,我们将这些不同的系统统称为具备智能体特征的系统(agentic systems),但在架构上,我们明确区分两类系统:工作流(Workflows) 这种系统的特点是:大语言模型(LLM)与各种工具的调用顺序,由事先定义好的代码逻辑所控制。智能体(Agents) 与工作流不同的是,在智能体系统中,大语言模型能够自主决定如何运用工具、动态地引导整个任务的执行过程,从而具备更强的自主性。
归纳下来主要就是这几点区别:
- AI Agent 能和外部环境交互
比如它能使用工具读取本地文件;能读取远程网页
- AI Agent 能动态的使用工具
比如我如果只是输入要翻译的文本,它就不会调用任何工具,如果我在一段文本中包含一个要翻译的网址,它就会从中提取要翻译的网址,并抓取内容再翻译
- AI Agent 能决定任务是否完成
举例来说,如果我的指令不是简单的翻译某一个网址,而是比较复杂的指令,像下面这样的:
请访问这个博客https://ingrids.space/并将前两篇文章的内容翻译为中文
那么它就会先抓取首页,然后分析首页的内容,找到前两篇文章的链接,再去分别抓取前两篇文章,最后再一起翻译,在这个过程中它使用了三次网页抓取工具,直到它认为已经完成任务了才会停止工具的调用。(这个使用案例的截图我放在文章后面了,有兴趣可以看看,或者自己下载代码运行试试看)
Agent 能处理高度复杂的任务,但它们的实现通常很简单本质上就是 LLM 利用环境反馈在循环中调用工具。连 Claude Code 这样复杂的 AI Agent,底层原理都是这样的,也是不停的调用工具,直到完成任务为止,就像下面这张图。
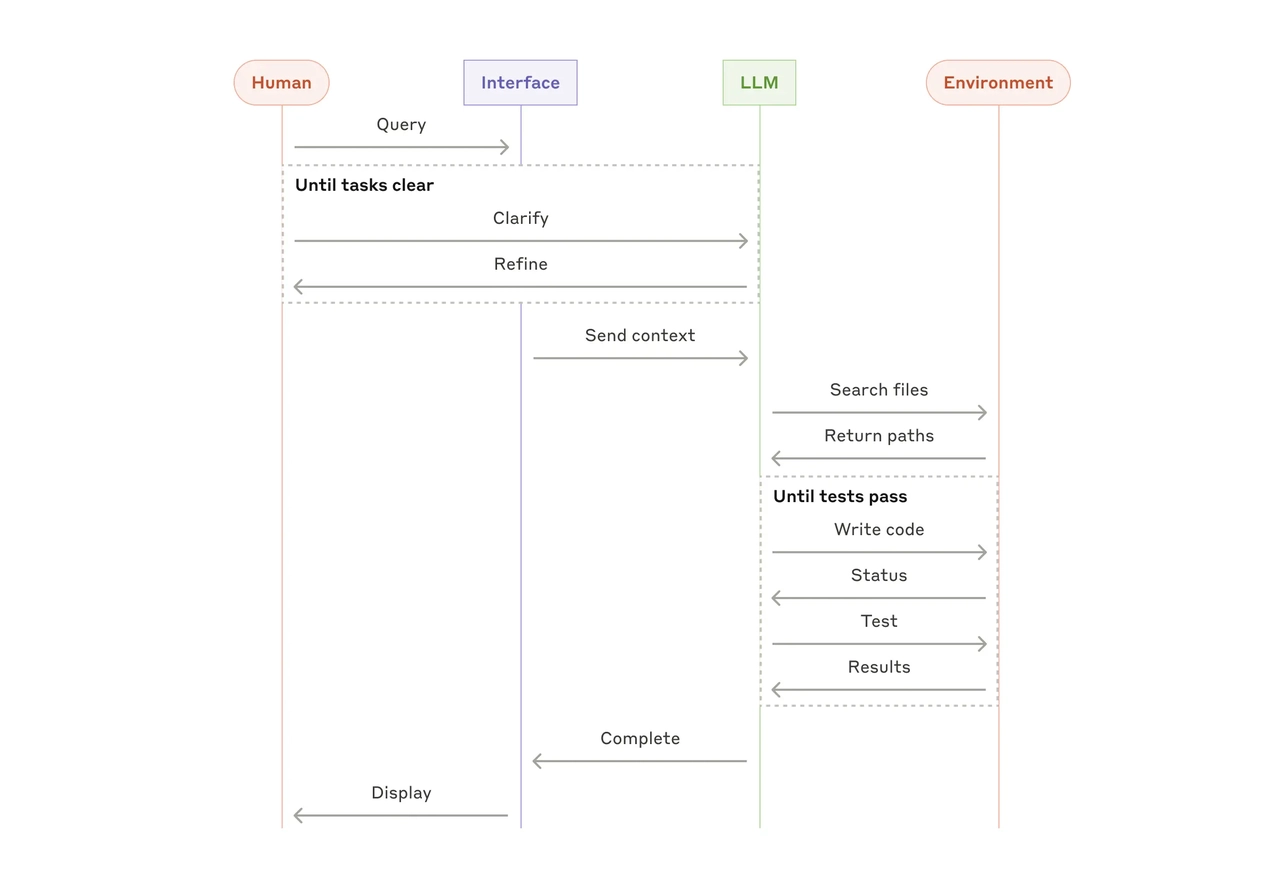 Claude Code 和普通 Agent 主要的不同在于 Claude Code 能启动子 Agent,也就是它能开分身,把分身当作自己的一个工具来用。就好比一个 AI 程序员,要去实现一个相对复杂一点的功能模块,它会先调用 TODO 工具,把任务分解,然后每个子任务让自己的分身去实现模块,分身只需要专注的完成子任务,这个分身有 AI 程序员本体一样的能力,也能调用所有的工具,等它完成子任务了,AI 程序员再让新的分身去继续下一个任务,直到所有任务完成为止。
Claude Code 和普通 Agent 主要的不同在于 Claude Code 能启动子 Agent,也就是它能开分身,把分身当作自己的一个工具来用。就好比一个 AI 程序员,要去实现一个相对复杂一点的功能模块,它会先调用 TODO 工具,把任务分解,然后每个子任务让自己的分身去实现模块,分身只需要专注的完成子任务,这个分身有 AI 程序员本体一样的能力,也能调用所有的工具,等它完成子任务了,AI 程序员再让新的分身去继续下一个任务,直到所有任务完成为止。
为什么我在这里选用的是豆包 1.6 模型呢?
在实现这个智能体的过程中,我使用的是豆包 1.6 的模型。主要是因为像 AI Agent 这样的任务,普通的大语言模型并不擅长调用工具,即使是普通推理模型都不行,必须要经过专门针对工具调用强化学习(RL)过的模型。简单理解就好比一个大学生,每天要反复练习怎么使用各种工具,用对了工具就有奖励,没用对就没有奖励,这样经过一段时间的学习后,就会特别擅长使用各种工具。只有这样经过强化训练的模型才能胜任好 AI Agent 的任务。目前主流的模型除了豆包 1.6,还有 o3、Claude 4、Gemini 2.5 Pro 来开发 Agent 都很好,豆包 1.6 相对性价比是很高的,国内使用也没有封号的风险。
另外火山引擎提供了 MCP Servers,像一些第三方工具可以方便的集成,比如我现在自己实现的网页抓取就很简陋,大部分网页其实都抓不了,如果要让它兼容更多网页,最简单的选择就是去选一个成熟的网页抓取的 MCP 服务,或者后面要支持 PDF 的翻译,这些都能在火山引擎上找到对应的可用 MCP 服务。
怎么借助 Claude Code 开发一个 AI Agent
在开发这个翻译 Agent 的时候,我是用的 Claude Code 来开发的,几乎没有手动写代码就完成了这个翻译智能体的开发。但我在这里还是要说明一下,Vibe Coding 并没有那么神奇,没有谁能不懂代码就做出成熟的产品。我之所以能这么快借助 Claude Code 开发出来,只是因为我用 Claude Code 开发之前,我已经半手工的写了好几个版本了,反复完成了几个试验品后,把需求理清楚了,把技术栈确定了,把一些坑踩完了,再让 AI 写就没那么复杂了。
当然这个过程肯定还是有可以学习和借鉴的地方,所以我把所有和 AI 交互的记录都一起放在 GitHub 上了https://github.com/JimLiu/agent-translator,如果你有兴趣可以看我是怎么从头构建这个项目的。
要让每个版本都独立可以运行
新手使用 AI 编程容易犯的一个错误就是一次憋一个大版本,期望一个版本内把所有功能都实现了,让 AI 写了一堆代码,最后合并在一起无法正常运行,跑起来到处都是 Bug。
所以借助 AI 编程的最佳实践,一定是要小版本迭代,并确保每个版本都能正常运行,充分测试后再下一个版本。就像你要造汽车,第一步先造个滑板车,然后自行车、再摩托车、最后再汽车。
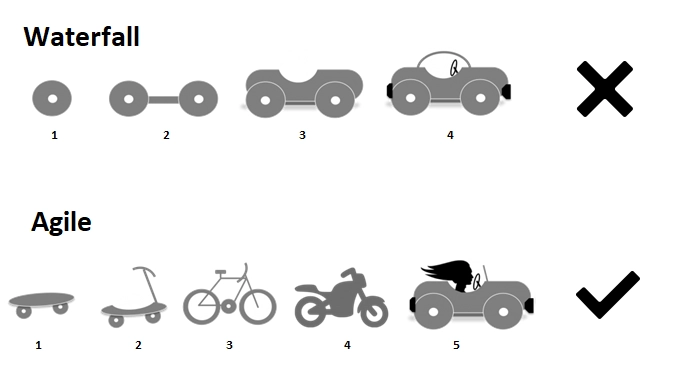 就像我这个翻译 Agent,我分成了几个版本迭代:
就像我这个翻译 Agent,我分成了几个版本迭代:
- v0: 初始化项目说明,设定好 CLAUDE Code 的规则,比如要求 Claude Code 每次生成完要自己测试,有错误自己修复
- v0.1:一个只有 UI 的程序,没有任何后台功能
- v0.2: 接上豆包 1.6 模型,让它可以实现简单的聊天对话
- v0.3: 添加了网页抓取和文件读取工具,并且让 LLM 可以接上工具
- v0.4: 把工具调用的状态和工具返回结果显示在 UI 中
这里面每一个版本都是可以独立运行的。
怎么写好 AI 编程的提示词
很多人觉得写提示词似乎要个模板才能写好,但实际上写提示词没你想的那么复杂,我把每个版本的提示词都放在 GitHub 上了,你完全可以照着复现整个过程。
1、描述清楚需求
让 AI 写代码的提示词,本质上就像你是一个产品经理+技术经理,把每个版本、模块的要求定义清楚,把技术规范说清楚。比如我第一个版本的提示词很简单:

2、把全局要求放在Claude.md文件上
我在第 0 个版本就是初始化Claude.md,说明清楚我要做一个什么产品,有哪些主要功能,技术栈是什么,每次开发后一定要自己测试等等。这样后续就不用每次说这些细节
3、要加上参考代码
现在 AI 的训练截止日期一般都是 2024 年的,这期间很多代码库都更新了,比如我用的 AI SDK,在我前几天测试的时候,AI 总是生成老版本的代码,导致很多问题,所以这次我每次实现前,都去官方文档把最新的代码示例都复制下来放到提示词里面,这样就不担心 AI 生成代码时过于老旧。
 4、出问题后有时候回滚好过继续修复
4、出问题后有时候回滚好过继续修复
在第一次实现 v0.3 版时,测试后结果很不理想,主要还是我复制 ai sdk 的参考代码时搞错了,虽然我可以让它基于错误的代码修正,但这种情况下要改对反而不太容易,不如直接回滚到 v0.2,修改提示词后重新开始。结果修改提示词后一次就成了。
最后
上面就是我用 ClaudeCode 做了一个基于豆包 1.6 模型的翻译智能体的分享。几点心得:
1、无论是学习 AI Agent 还是 AI 编程,最好的学习方法还是动手实践,只有动手实践过才能真正掌握好
2、AI 编程可以提升效率,但是要用好,要学会描述清楚需求,学会划分版本拆分模块
3、开发 AI Agent,要用适合 AI Agent 的模型,比如豆包 1.6、o3、Claude 4、Gemini 2.5 Pro,不然你再怎么优化提示词效果可能也不理想
项目地址:https://github.com/JimLiu/agent-translator
附录
让翻译 Agent 从博客首页找到前两篇文章并翻译的示例
