阿里云发布 Qwen-TTS 高性能语音合成模型(Text-to-Speech,TTS)。其核心能力是将输入的中英文文本转换为具备自然表达力的语音输出。
与传统 TTS 模型相比,Qwen-TTS 最大的亮点在于:
- 高自然度:声音表达更接近真人,具备情感、节奏、语调变化;
- 多语种与方言支持:目前支持普通话、英文,以及三种中文方言(北京话、上海话、四川话);
- 多音色选择:提供不同性别、语调和口音的声音,适配多样化场景。
语言与方言支持细节
支持的语音变体:

真实合成样例:https://qwenlm.github.io/zh/blog/qwen-tts/
技术原理与数据基础
- 大规模训练语料支撑
模型训练使用了超过 300 万小时的语音数据,包括中英文对齐数据以及丰富的方言语料,这使得模型不仅语音自然,而且能模仿不同地区的说话风格。
- 韵律与情感建模
Qwen-TTS 支持自动调整文本的语速、重音、节奏和情绪表现。例如,在表达惊讶、温柔或愤怒时,语音会自动体现相应情感,而无需显式标注。
- 音色建模与风格迁移
- 模型通过“音色编码”技术,使得同一句话可以生成多种风格(如男声/女声、北方口音/南方口音)的语音输出。
当前支持 7 种音色:
- Cherry、Ethan、Chelsie、Serena(中英文)
- Dylan(北京话)、Jada(上海话)、Sunny(四川话)
性能评估:
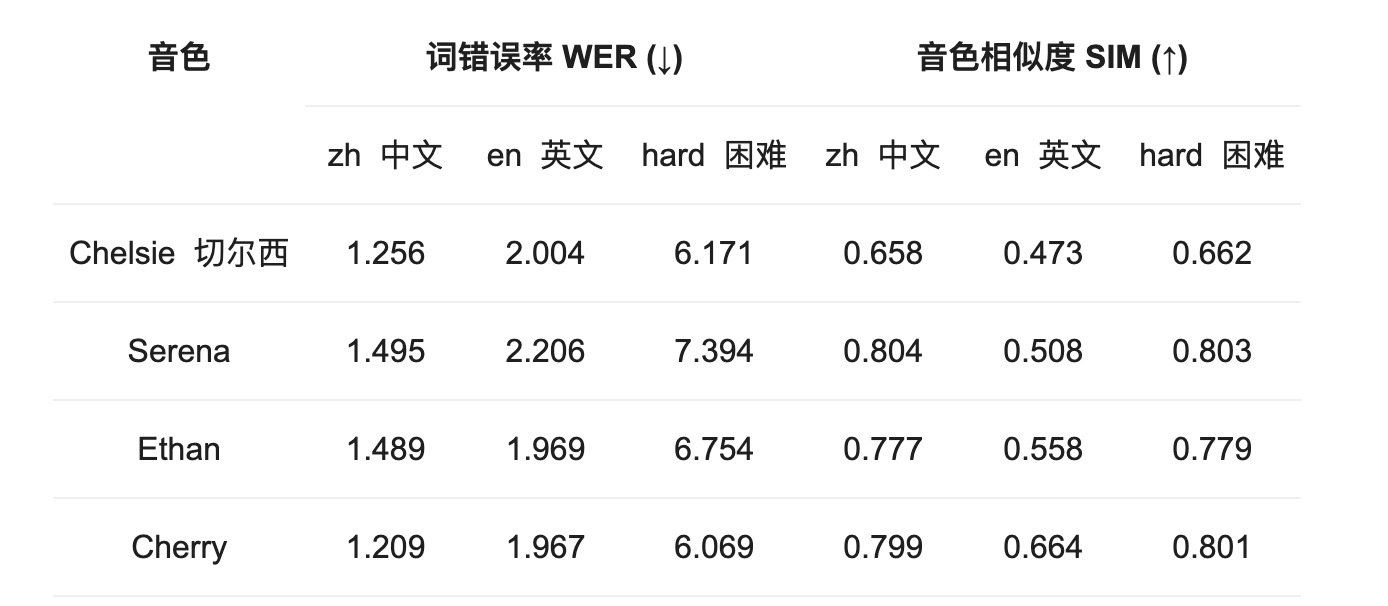
模型在 SeedTTS-Eval 评测集上的指标如下:
核心指标:
- WER(词错误率):表示语音识别回转文本的准确率,越低越好;
- SIM(音色相似度):衡量生成音色与目标音色的接近程度,越高越好。
如何使用:API 与代码接入方式
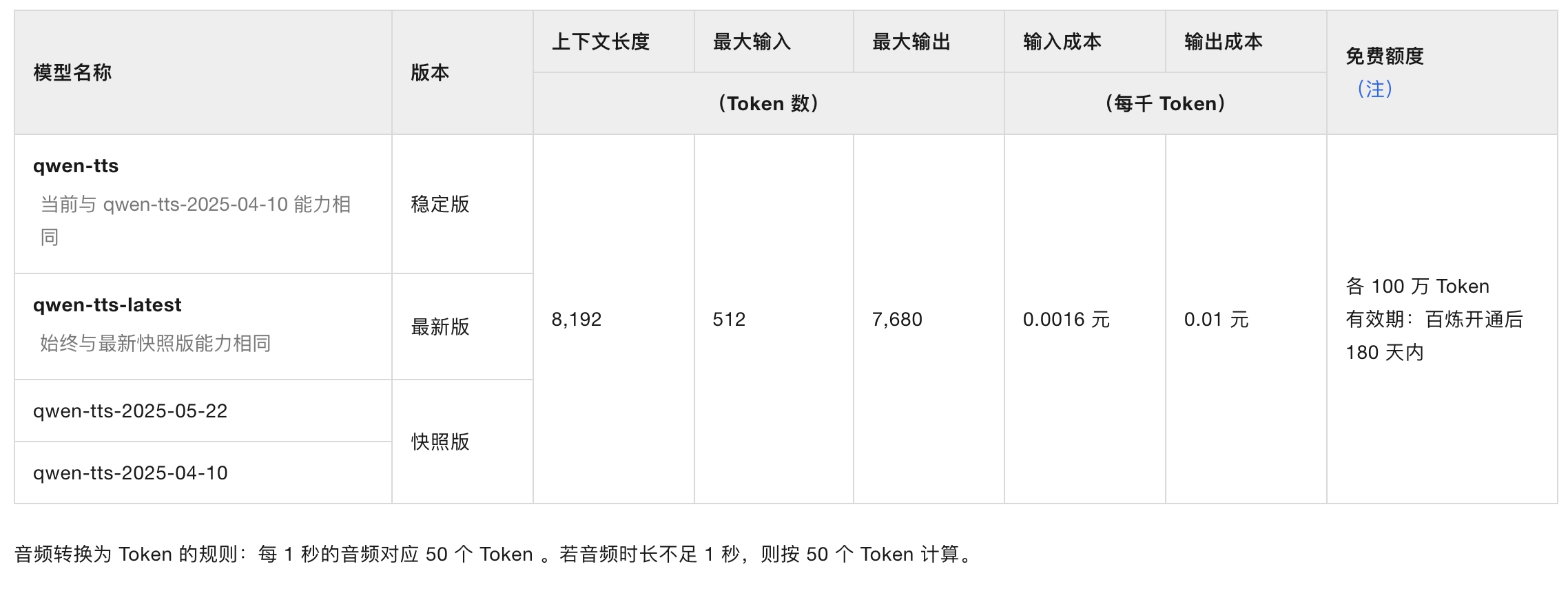
价格:
Qwen-TTS 通过 Qwen API 的方式提供,用户可通过如下 Python 示例调用模型完成语音合成任务:
基本流程:
- 设定 API 密钥(DashScope API);
- 设定合成语句、目标音色和模型版本;
- 调用合成函数,获取音频链接;
- 下载并保存音频文件。
示例代码片段(简化):
``` import os import requests import dashscope
def getapikey(): apikey = os.getenv("DASHSCOPEAPIKEY") if not apikey: raise EnvironmentError("DASHSCOPEAPIKEY environment variable not set.") return api_key
def synthesizespeech(text, voice="Dylan", model="qwen-tts-latest"): apikey = getapikey() try: response = dashscope.audio.qwentts.SpeechSynthesizer.call( model=model, apikey=api_key, text=text, voice=voice, )
# Check if response is None
if response is None:
raise RuntimeError("API call returned None response")
# Check if response.output is None
if response.output is None:
raise RuntimeError("API call failed: response.output is None")
# Check if response.output.audio exists
if not hasattr(response.output, 'audio') or response.output.audio is None:
raise RuntimeError("API call failed: response.output.audio is None or missing")
audio_url = response.output.audio["url"]
return audio_url
except Exception as e:
raise RuntimeError(f"Speech synthesis failed: {e}")
def downloadaudio(audiourl, savepath): try: resp = requests.get(audiourl, timeout=10) resp.raiseforstatus() with open(savepath, 'wb') as f: f.write(resp.content) print(f"Audio file saved to: {savepath}") except Exception as e: raise RuntimeError(f"Download failed: {e}")
def main(): text = ( """哟,您猜怎么着?今儿个我看NBA,库里投篮跟闹着玩似的,张手就来,篮筐都得喊他“亲爹”了""" ) savepath = "downloadedaudio.wav" try: audiourl = synthesizespeech(text) downloadaudio(audiourl, save_path) except Exception as e: print(e)
if name == "main": main()
```