埃隆·马斯克(Elon Musk)通过直播发布了其人工智能公司xAI的最新语言模型Grok 4。
Grok 4被马斯克称为“世界上最聪明的AI”,在综合学术基准测试“人类最后的考试”(Humanity's Last Exam)中取得了约25%的准确率,与OpenAI的Deep Research工具相当 。
- 多模态能力:初始版本支持文本输入,未来计划加入图像生成、视频和音频处理功能,以实现更丰富的交互体验 。
双版本发布:
- 通用版:适用于日常写作、研究、翻译等任务,支持函数调用、结构化输出和高级逻辑推理。
- Grok 4 Code:专为开发者设计,集成代码生成、错误检测和上下文软件开发辅助功能 。
语音模式升级:新增五种语音模式,包括一位名为Eve的英国口音AI助手,具备表达性语音和歌唱能力 。

功能特性
Grok 4 的设计强调实用性和专业化,分为通用版(Grok 4)和编程专版(Grok 4 Code),旨在为日常用户和开发者提供高效工具。核心功能包括以下方面:
1.推理与逻辑能力:
- 采用“第一性原理”推理方法,提高逻辑一致性和深度分析能力,能够模拟物理学家式的思考过程,处理复杂问题如跨学科知识整合。
- 声称“在所有学科优于几乎所有研究生”,包括自然语言处理、数学和跨领域知识。
- 支持实时学习和适应用户需求,实现高度自定义化,例如根据用户反馈调整响应风格或集成现有工作流程。
2.编程与代码相关:
- Grok 4 Code 是专为开发者设计的变体,支持代码生成、调试、创建完整应用、游戏、文档和网页。
- 内置代码解释器,提升编码效率,与 GPT-4 等模型相比,在代码开发中表现出色,但强调更强的数学准确性和逻辑推理。
- 支持工具集成,如函数调用、外部 API 触发(例如查询天气或订票),并提供结构化输出(如 JSON 格式),便于系统对接。
3.多模态支持:
- 初始版本支持文本到文本模态,以及图像解释功能,能够处理上传的图片并生成描述或修改。
- 视觉和图像生成能力即将推出,未来几个月内将扩展到视频生成和更全面的多模态交互(如文本生成图像/视频)。
技术规格:
- 上下文窗口为 256k tokens(优于大多数模型,低于 Gemini 2.5 Pro 的 1M)
- 支持图文输入
- 支持函数调用和结构化输出
4.其他功能:
- 集成 Polymarket 支持赌博相关查询,以及 Grok Voice 的 ASMR Goon Mode,提供合成语音交互。
- 图像编辑功能:用户可上传照片,描述修改需求,模型生成编辑版本。
- 强调“真实信息”导向,允许政治不正确的表述(若有依据),并在处理时事时分析多方来源以减少偏见。
性能表现
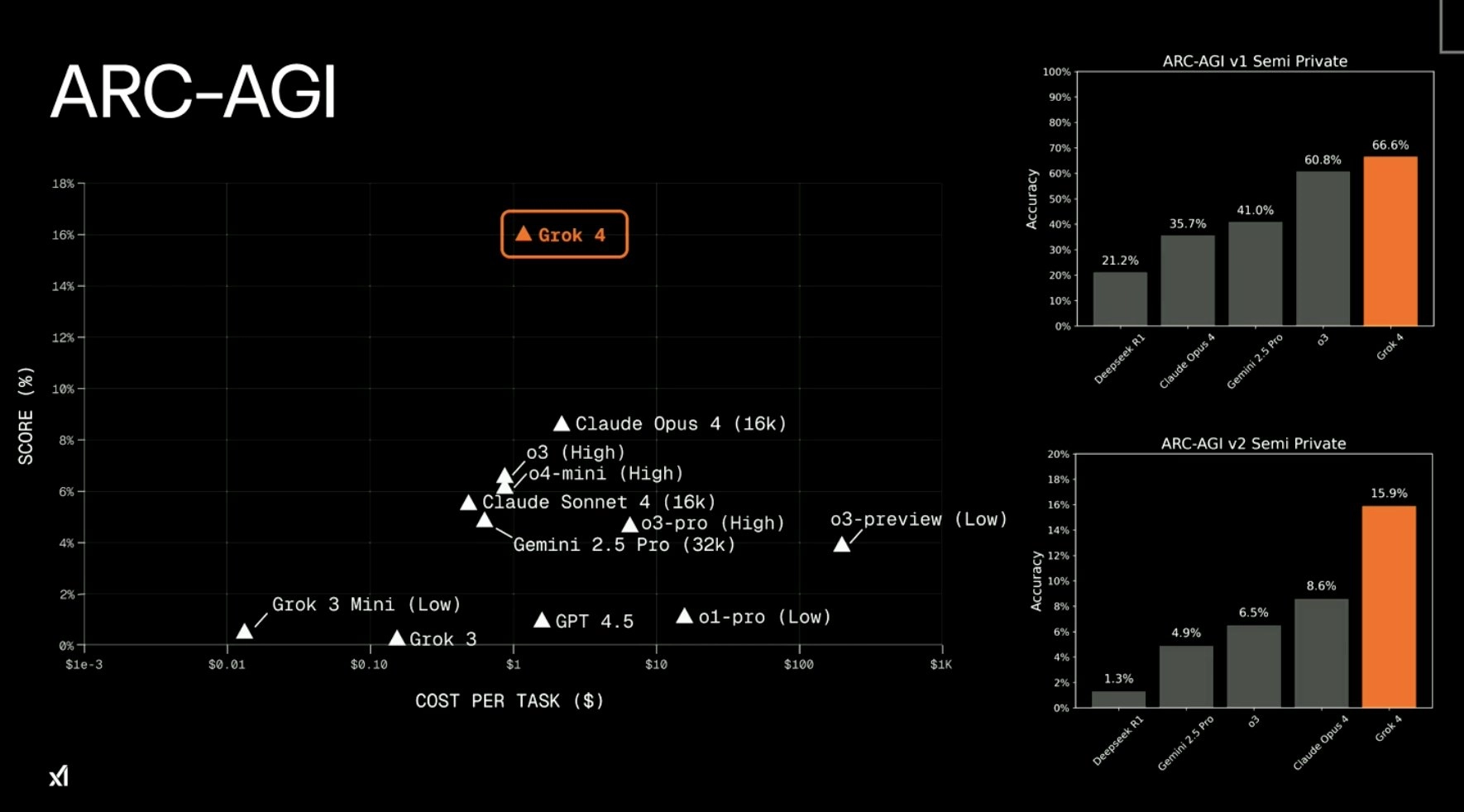
Grok 4 的性能通过泄露基准测试和官方声明展示出显著提升,尤其在数学、编程和推理领域。马斯克宣称其在所有科目达到 Ph.D. 水平,无例外。
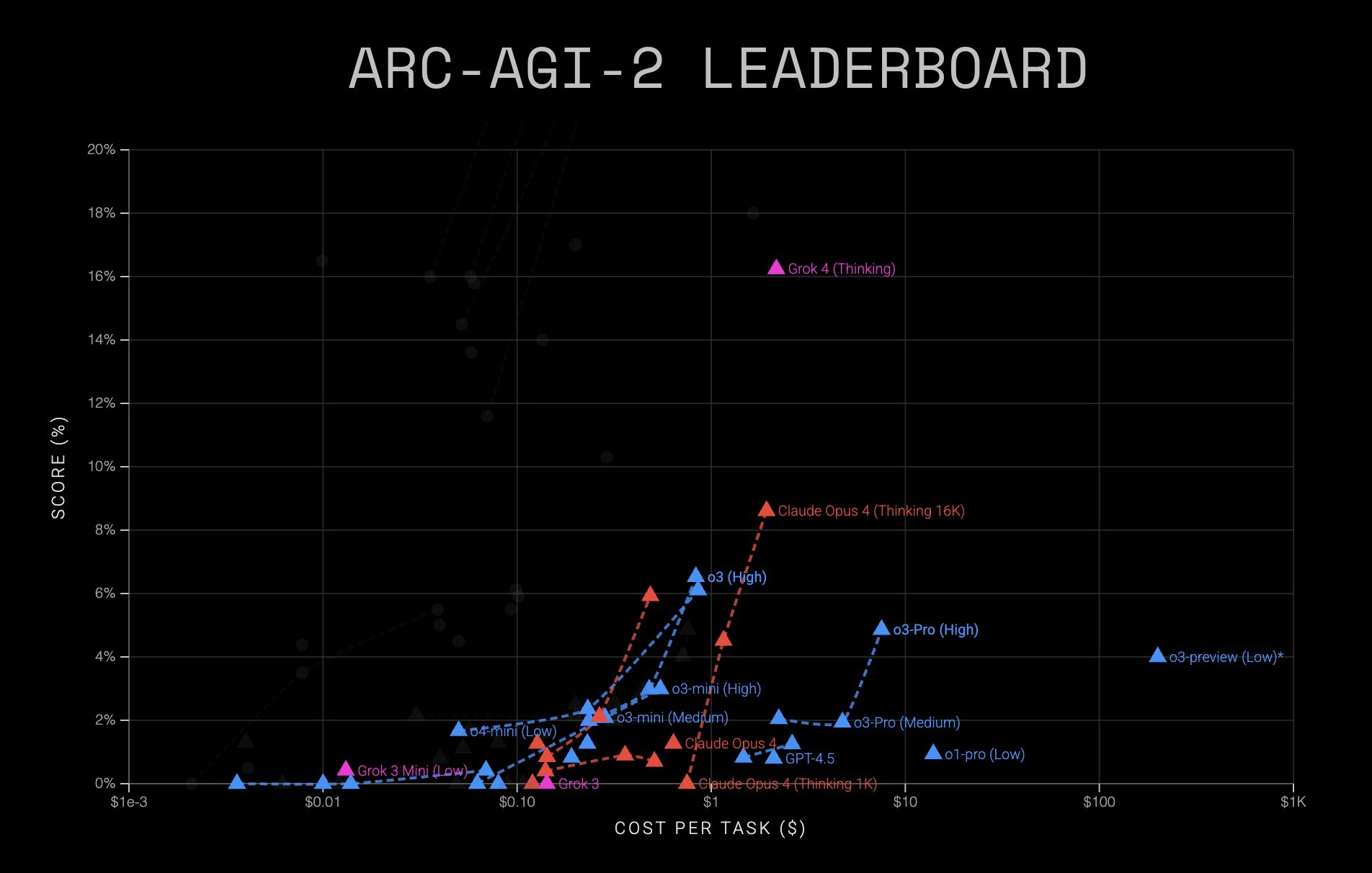
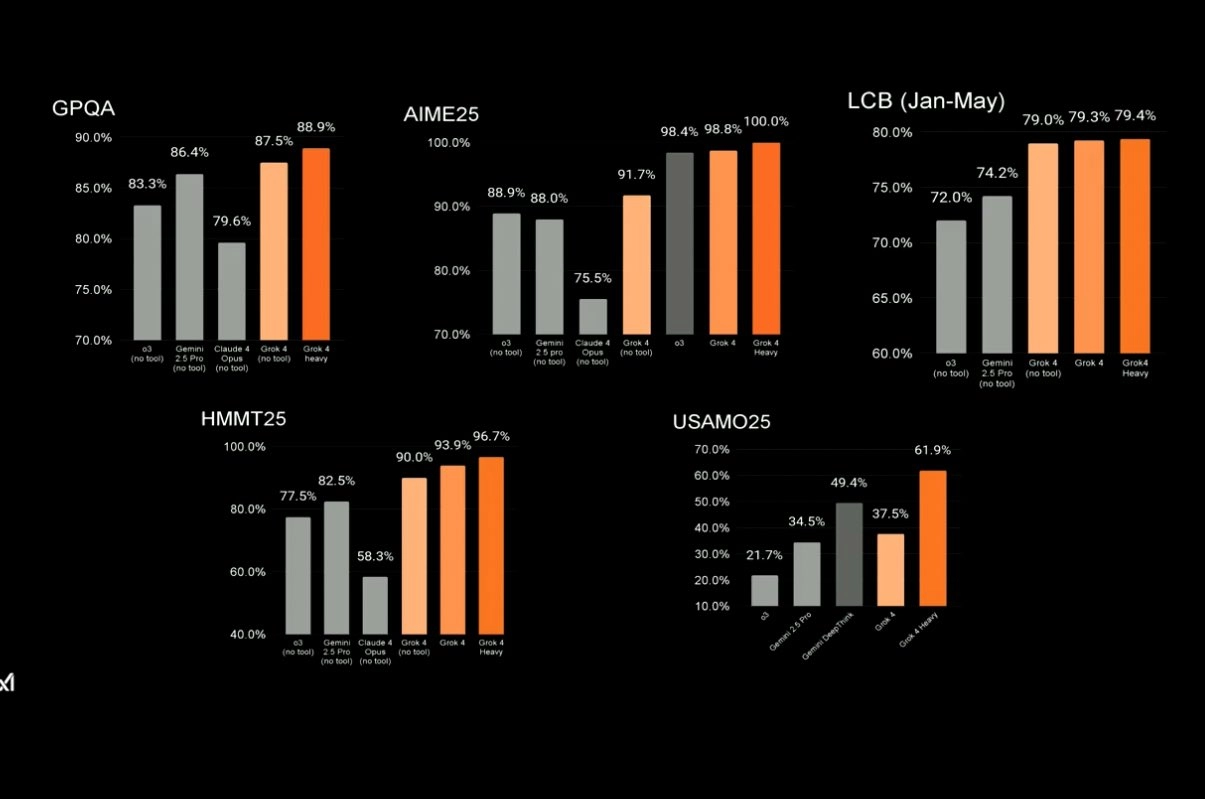
Grok 4(思考)在 ARC-AGI-2 上取得了新的 SOTA,达到了 15.9% 这几乎是之前商业 SOTA 的两倍,并且领先当前 Kaggle 竞赛的 SOTA
以下是关键基准数据(部分基于泄露,可能未经官方最终确认)。
基准测试成绩:
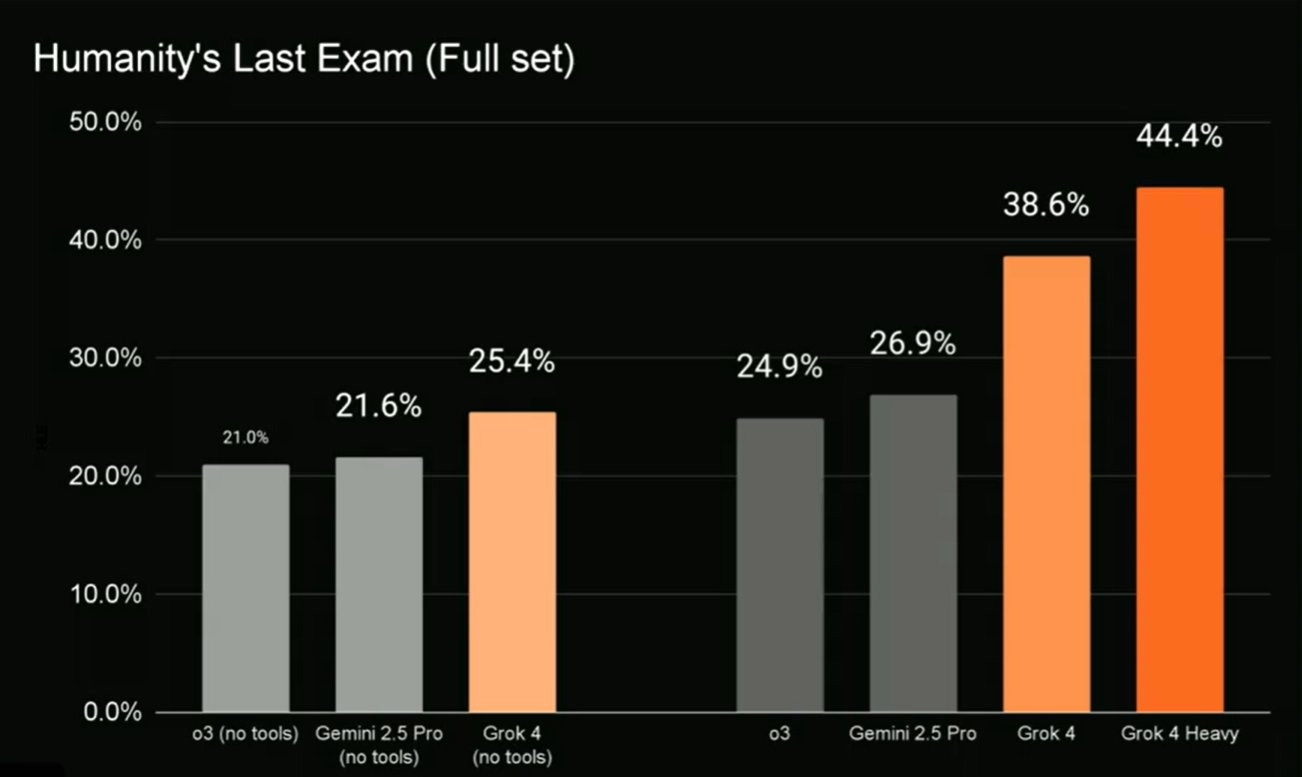
Humanity's Last Exam (HLE):Grok 4 得分 45%,远超 Gemini 2.5 Pro 的 21%,以及其他模型。该测试评估跨学科 Ph.D. 级知识,Grok 4 Heavy(带工具版)得分 44.4%,优于 Gemini 2.5 Pro 的 26.9%。
- AIME 2025 (美国数学邀请赛):准确率 95%,突出其数学能力,与人类专家相当。
其他评测:在 GPQA、SWE-bench 等编程和推理基准中表现优异,编程能力与 Claude 并列第一。Grok 4 Code 在编码任务上大幅领先竞争对手。
与竞争对手比较:
- 优于 GPT-4:在逻辑推理、数学准确性和编码智能上更强,尤其在工具集成场景。
- 挑战 Claude 和 Gemini:在自然语言处理和多模态任务上表现出色,但基础功能(如避免 bug)仍有改进空间。
- 整体优势:训练于 Colossus 超级计算机,提供 10 倍计算提升,实现更快响应和更深推理。
潜在争议:
- 部分基准(如 HLE 45%)引发质疑,可能涉及实验设置或数据不透明。早期版本 Grok 3 曾因基础问题被批评,Grok 4 在推理优势基础上需完善稳定性。
人工分析智能指数(Artificial Analysis Intelligence Index):Grok 4 得分 73,超过 OpenAI o3 和 Google Gemini 2.5 Pro(均为 70)。
首次登顶:Grok 4 是 xAI 首次在该机构的智能指数中排名第一。
测试方式:使用 xAI API 进行测试,注意 Twitter/X 上的版本可能行为不同。
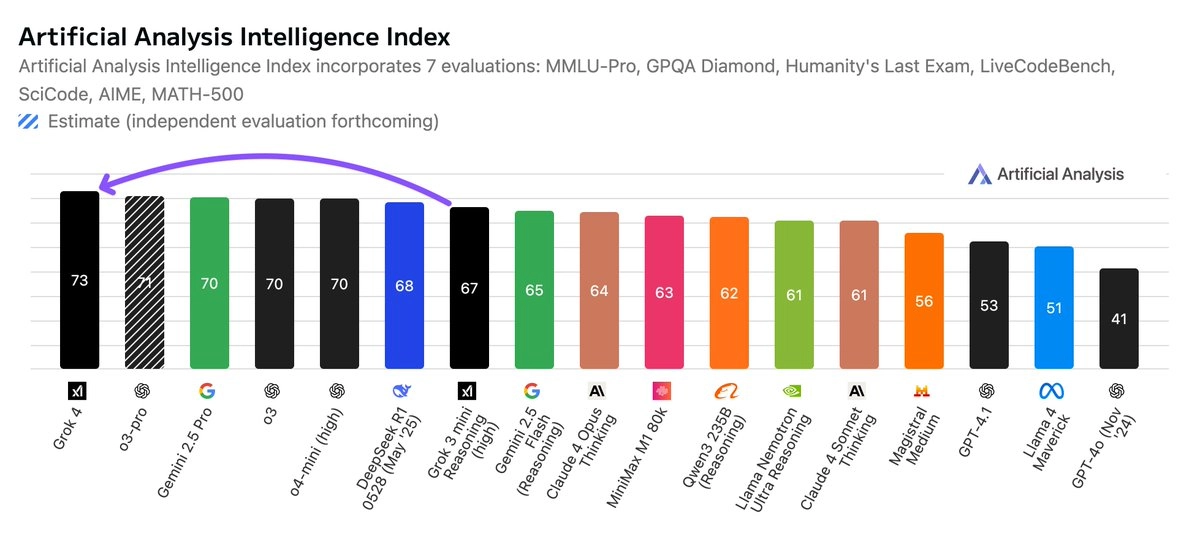
领先模型对比得分:
- Grok 4:73
- OpenAI o3:70
- Gemini 2.5 Pro:70
- Claude 4 Opus:64
- DeepSeek R1 0528:68
在多个子基准测试中创下新纪录:
- GPQA Diamond:88%(历史最高,超过 Gemini 的 84%)
- Humanity’s Last Exam:24%(历史最高,超过 Gemini 的 21%)
- MMLU-Pro:87%(并列最高)
AIME 2024:94%(并列最高)
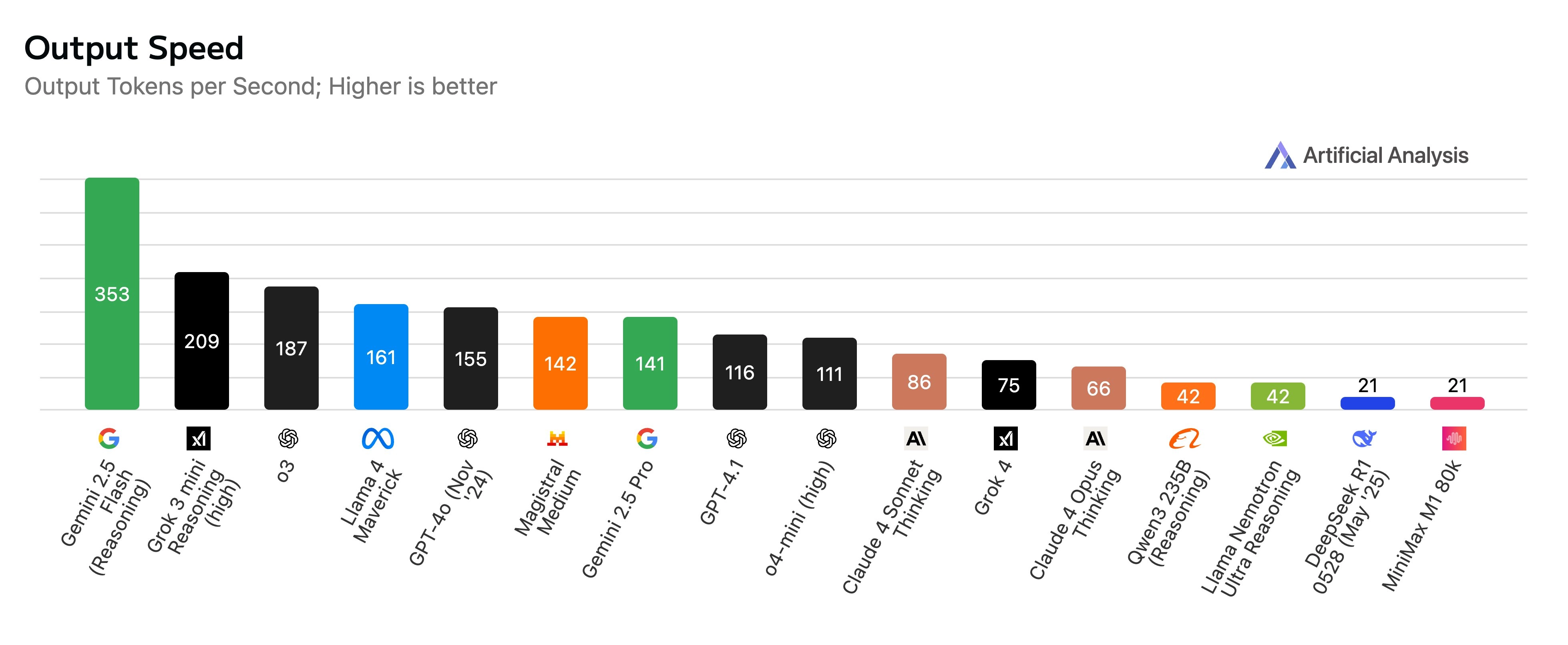
速度对比(token/s):
- Grok 4:75
- o3:188(最快)
- Gemini 2.5 Pro:142
- Claude 4 Sonnet Thinking:85
Claude 4 Opus Thinking:66(最慢)
价格:
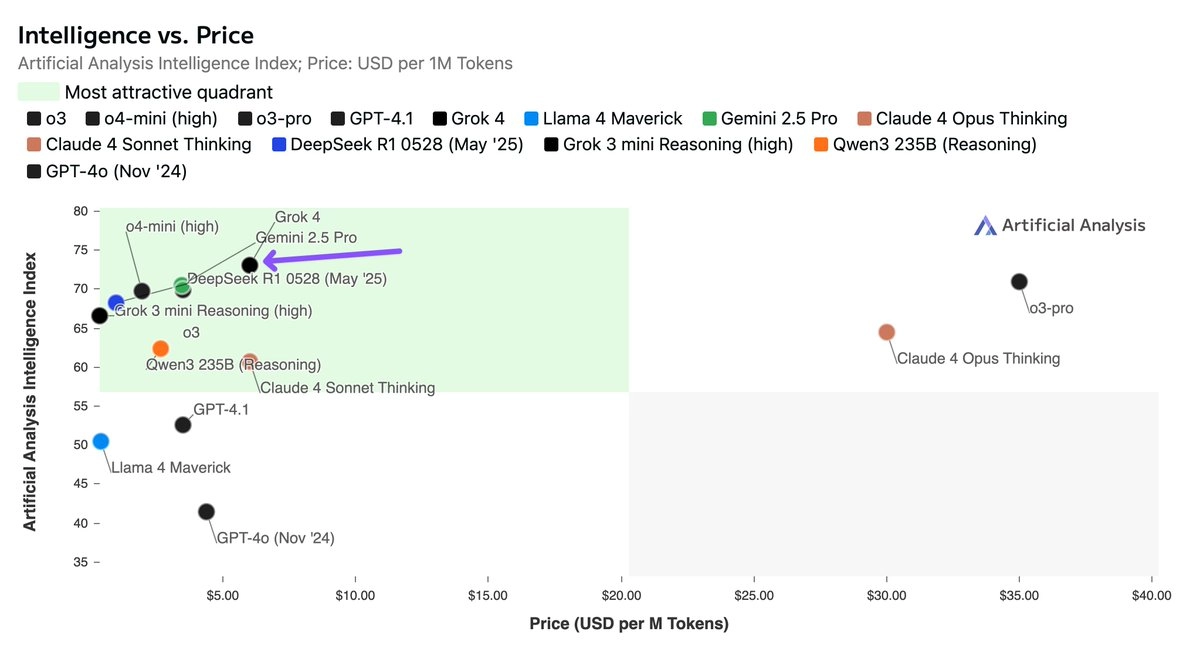
- Grok 4 定价与 Grok 3 相同:$3/$15 每百万输入/输出 token。
- 与 Claude 4 Sonnet 相同,但贵于 Gemini 2.5 Pro 和 o3。
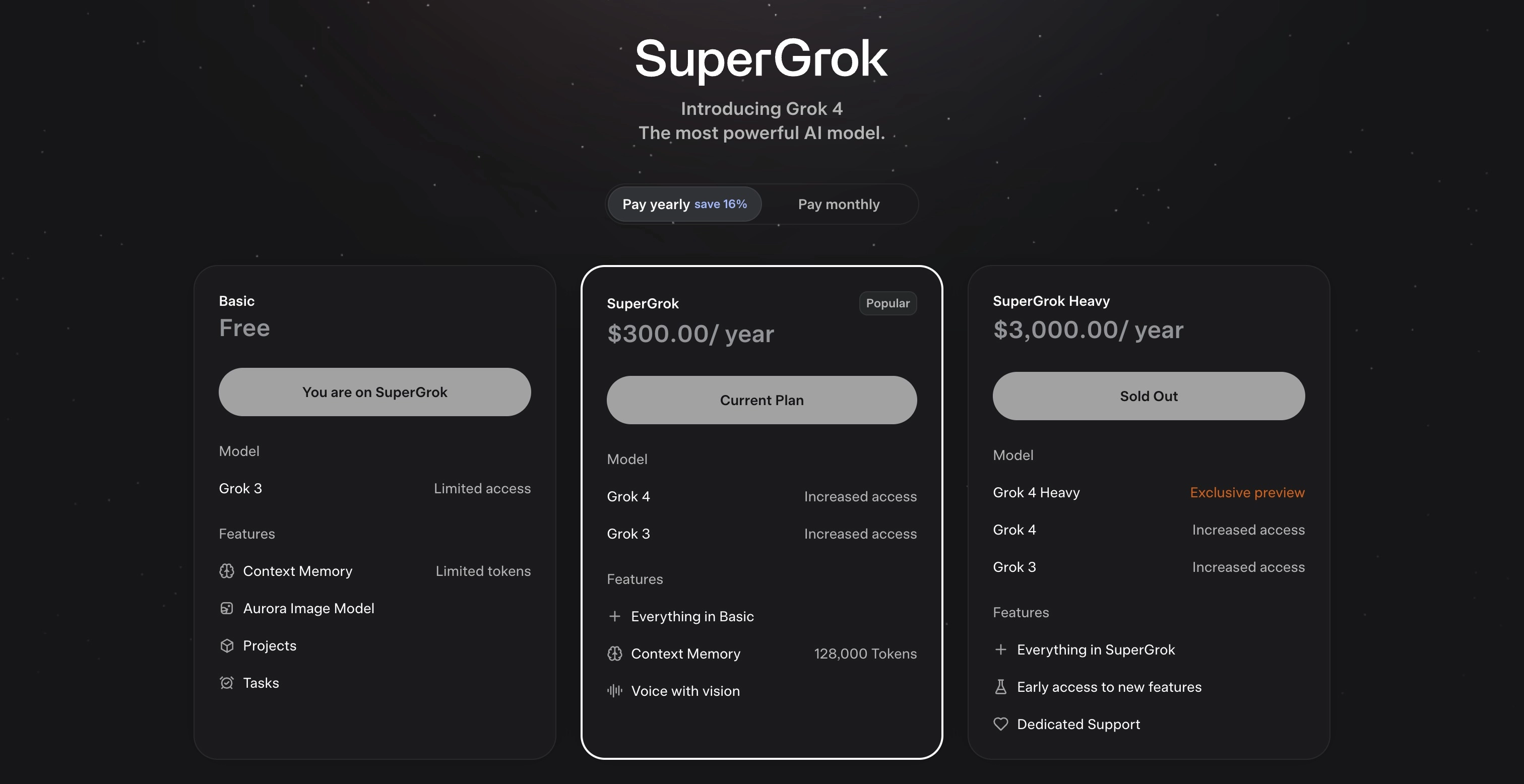
xAI还推出了名为“SuperGrok Heavy”的高级订阅计划,月费为300美元。订阅者将获得Grok 4 Heavy版本的独家访问权限,以及未来功能的抢先体验。