2025年,AI 大模型技术已步入竞争白热化阶段,中国厂商如智谱 AI 与阿里通义在全球舞台上持续发力,推出了多款在推理、代码生成、Agent 能力等方面表现卓越的顶级模型。其中,GLM-4.5系列与Qwen3系列被视为最具代表性的代表作,深受开发者与研究机构关注。
那么,哪一款模型在综合能力上更胜一筹?本文将从架构、参数规模、基准测试、工具调用、推理能力等方面进行全方位对比,并推荐一个超好用的模型信息平台 ——AIbase 模型广场,助你全面掌握全球大模型格局。
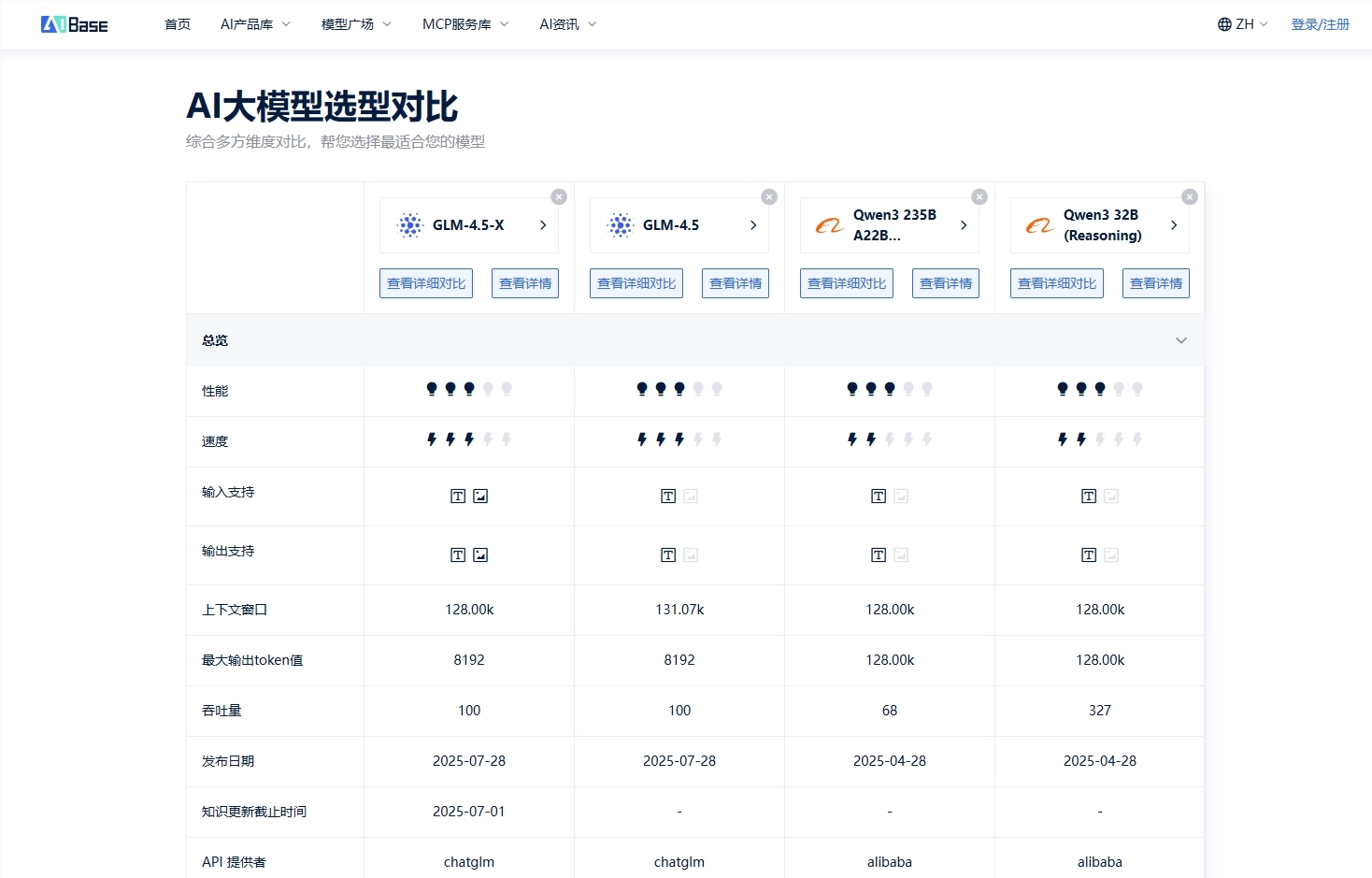
开发方:智谱 AI(Zhipu AI)
架构类型:Mixture of Experts(MoE)
总参数量:约355B(激活参数32B)
上下文长度:支持128K
优势亮点:
在12个主流 Benchmark 中综合表现全球第三,仅次于 GPT-4和 Grok-1。
在编码任务中胜率超过 Qwen3-Coder,高达80.8%。
工具调用(如搜索、函数调用)成功率达90.6%,表现优于大多数开源模型。
多语言处理与推理能力稳定,支持 Agentic 推理链执行。
GLM-4.5-X 是该系列的升级版,在数学、多跳推理和调用复杂 API 方面表现更为出色,是目前开源模型中极具竞争力的存在。
开发方:阿里通义(Alibaba Qwen)
架构类型:MoE(专家路由)+ Hybrid 推理模式
总参数量:约235B(激活参数22B,动态调用8个专家节点)
上下文长度:最高支持256K
优势亮点:
具备“Thinking”模式,可切换不同推理深度,按需调用专家模块,提升准确率同时降低计算资源消耗。
在 AIME、GPQA、AgentBench 等任务中表现与 Claude-Opus、Kimi-K2不相上下。
对中文任务优化明显,在语义理解、上下文保持等方面性能稳定。
适用于长文档摘要、复杂问答、代码补全等场景。
Qwen3-235B-A22B 的动态专家机制使其在功耗、性能之间实现出色平衡,是企业部署场景中的“高性价比”代表。
模型类型:稠密模型
参数量:约32B(无专家机制)
性能特点:
虽非 MoE 架构,但在编码、逻辑推理方面达到 DeepSeek-V3相近水平。
更适合轻量化部署、边缘计算或中型产品应用。
响应速度快、显存占用低,适合对响应时间有严格要求的场景。
一些开发者反馈:GLM-4.5-Air 版本加载速度快、显存需求更低,推理效率比 Qwen3-235B 高出一倍,尤其适合部署在高并发产品中。
Qwen3-235B 虽参数更大,但专家机制使其在推理成本方面不输中小模型,并能适配复杂任务分级响应。
两者均支持大窗口输入场景,但在实际文档摘要与数据问答方面,GLM-4.5的“稳准快”体验略胜一筹。
如果你正在寻找一个全面、准确、可对比的模型查阅平台,强烈推荐使用AIbase 模型广场。
收录数百个主流模型,支持对比如 GLM-4.5、Qwen3系列、LLaMA、DeepSeek、Claude 等;
分类清晰:按模型架构、参数规模、推理能力、支持语言、上下文长度等多个维度筛选;
实时更新 Benchmark 数据和调用能力表现;
支持模型官网跳转、使用入口、API 文档链接查看,是开发者和研究者不可或缺的工具箱。
通过 AIbase 模型广场,你可以一站式掌握全球大模型排行榜、参数详情、评测结果,快速找到适合自己的大模型产品。
如果你追求的是全面性能、代码能力、工具调用与推理稳定性,GLM-4.5-X 无疑是当前开源模型中的头部之选。
如果你更看重推理成本与部署效率,Qwen3-235B-A22B 的混合专家架构非常适合大规模商业落地。
对于轻量场景、模型试验或中型项目,Qwen332B 提供性价比极高的替代方案。
无论你选择哪个模型,借助AIbase 模型广场都能帮你快速对比参数与性能,掌握全球 AI 大模型发展趋势。