Hume AI 致力于打造具有情感理解能力的语音 AI,他们设定的目标是:到 2025 年底,提供完全个性化的语音AI体验。EVI 3 是他们的第三代“语音-语言”大模型,它不仅能听、能说,更能表达和理解情感,是面向未来“情感化AI交互”的重要里程碑。
EVI 3 是一个能“听懂你说话、带情绪地和你聊天”的AI助手,可以理解你的语音情绪并用你喜欢的声音与风格和你互动。
有哪些主要功能?
- 像人一样说话和回应你,包括用快乐、生气、害羞、疲惫等30多种语气与风格。
- 还能听出你声音里的情绪,做出自然、有共情的回应。
- 你可以设定AI的声音风格,比如“像海盗说话”,或者“温柔低语”。
- 对话不卡顿,几乎像真人聊天一样自然。
它解决了什么问题?
- 传统语音助手只会“照本宣科”,不理解你的情绪。
- 它的“边说边想”机制,让它可以一边说话,一边搜索、推理,不再只是单调的问答机器人。
- EVI 3 将“声音”变成一个真正有温度的交互界面,更贴近人类交流方式。
EVI 3 核心特点
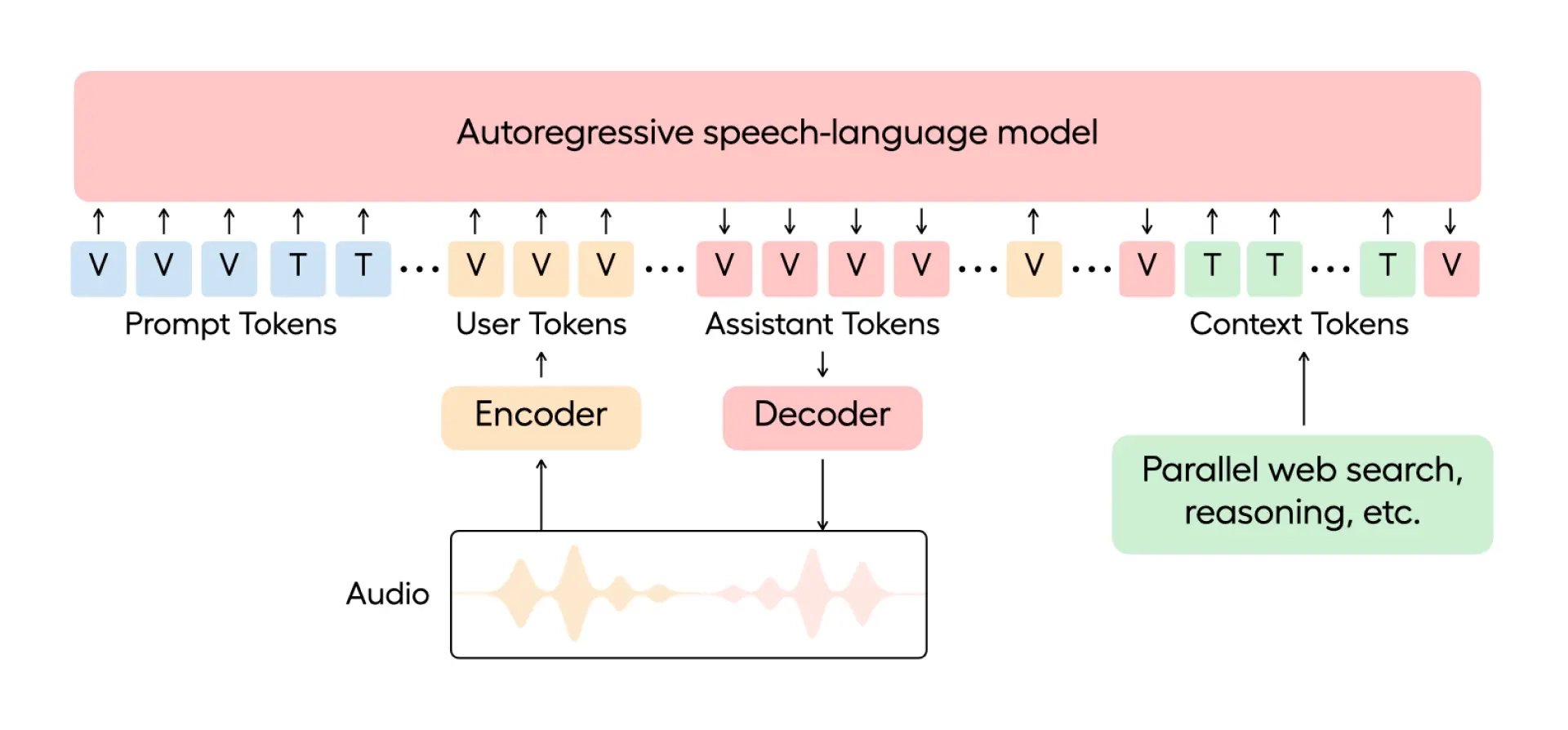
1. 一体化语音-语言架构(Speech-Language Architecture)
- 统一模型处理语音输入与输出:不像传统TTS(文本到语音)或ASR(语音识别)是分离的,EVI 3 使用一个自回归模型同时处理文字(T)和语音(V)token。
- 系统提示结构(System Prompt):包含语言和语音token,不仅定义交互内容,也控制语调、风格等行为表现。
2. 情绪与风格个性化表达能力
- EVI 3 可通过提示生成任意声音,并赋予其特定“性格”或“情绪风格”。
- 支持 超30种复杂语音风格:如“激动的”、“装作疲惫的”、“演海盗”等。
- 你可以通过提示词来创造 AI 的“声音”和“性格”,比如温柔型、幽默型、专业型等。目前已有超过10万个自定义声音在平台上生成,这种灵活性远超以往固定角色的语音助手。
- 与GPT-4o等模型相比,在表达真实感情与语调切换方面更精准自然。
3. 高效语音响应能力
- 实现 低于300ms的模型推理延迟。
- 实际应用中,EVI 3 在美西部署环境下响应时间为 0.9-1.4s,优于 GPT-4o(2.6s)与 Gemini(1.5s)。
4. 情绪识别(Voice Emotion Understanding)
- 支持从语音中识别情绪——无需文字,仅靠语调、节奏与声音特征。
- 在评测中,EVI 3 能准确识别 9种基础情绪,在8种上优于 GPT-4o,表现更自然。
5. 实时多任务能力(“边说边想”)
- 支持在语音输出过程中注入新的上下文token,同步进行搜索、推理、工具使用。
- 实现类似“系统并行”的智能响应机制,让AI在对话中像人类一样一边说话一边“思考”。
EVI 3 能够根据语境自动调整语气,也可以通过提示词明确控制风格。比如:
- 焦虑时口吃(stammers anxiously)
- 激烈辩论时语气高涨(debates enthusiastically)
- 私密对话中轻声细语(whispers intimately)
这让它在与用户交流时显得真实、自然、有情绪层次感,不再是千篇一律的语音输出。
用户只需一句提示,EVI 3 就可以在不到一秒内生成一个全新的声音和人格设定:
- “一个沙哑声音的澳洲历史爱好者”(raspy Australian history buff)
- “一个伶牙俐齿的英国恶作剧者”(sassy British prankster)
- “一个兴奋的加勒比音乐人”(excited Caribbean musician)
这使得 AI 不再是固定模板的语音助手,而成为高度可定制、风格多变的虚拟角色引擎,可用于游戏、影视、教育、虚拟助理等多种应用场景。
EVI 3 的创新与训练方法
1. 统一的语音-语言模型架构(Speech-Language Token Integration)
✅ 创新点:
EVI 3 将语音与文本信息统一建模,而不是像传统系统那样将语音识别(ASR)、语言处理(NLP)和语音合成(TTS)分别处理。
🔧 技术原理:
使用一个 自回归模型(Autoregressive Model) 来处理两类输入:文字 token(T)和语音 token(V)。
这些 token 被组合成一个**“系统提示”(system prompt)**,不仅提供语言上下文,还定义语音风格、语调和节奏。
可以边听边理解、边说边生成,形成自然的语音对话流。
📈 优势:
信息在不同模态之间流动顺畅,反应更自然。
模型更容易捕捉“说话方式”中的情感、风格和节奏等元素。
2. 个性化表达的训练策略
✅ 目标:
实现 AI 不再只使用预设的几种“声音”,而是能够根据提示实时生成多样的语音风格和人格特征。
🔬 方法:
- 大规模多说话人数据建模:不是为每种声音单独微调,而是训练一个模型能泛化出所有人类可能的声音。
- 使用带标签的风格/情感数据集,帮助模型学会“如何表达愤怒、高兴、害羞”等语气。
- 在推理过程中实时调节语音生成参数,根据提示词即时变化。
3. 强化学习优化输出质量
🎯 问题:
如何让模型输出的语音表现更接近用户偏好,比如“语气要更柔和一些”,“别太机械”?
🧠 解决方案:
- 引入 强化学习(Reinforcement Learning, RL) 技术,目标是优化模型的表达效果和用户反馈匹配度。
- 在用户与模型交互的基础上,模型学习哪些语音输出风格得分高、被认为“好听、自然、有情感”。
🏆 效果:
- 让模型自主“调整自己的说话方式”,越来越接近人类所喜欢的语音风格。
4. 流式语音生成机制(Streaming Voice-to-Voice Processing)
🔧 技术挑战:
传统语音生成是“听完再说”,会造成延迟、不连贯。
✨ 解决方案:
- EVI 3 实现了流式处理(Streaming Generation),可以在说话过程中动态调整生成内容。
- 支持在语音输出时注入新的上下文,比如用户正在提问时,AI 就能实时进行搜索、推理、调用工具等。
🧩 模型机制图示(文解):
一个统一的模型不断接收输入(语音 + 文字 token),在生成语音回应时,可以插入“搜索结果”、“工具调用反馈”等内容,实时融入回答中。
5. 高效延迟控制与部署优化
🚀 优化方向:
EVI 3 的目标是提供接近人类的对话体验,所以必须做到低延迟语音交互。
⚙️ 实现方法:
- 通过优化模型架构与部署方式,使得语音响应低于 300 毫秒;
- 对用户来说,整体响应时间(包括网络等因素)控制在1.2 秒以内,比 GPT-4o 和 Gemini 更快。
✅ 总结:EVI 3 在研究方法上的五大突破

EVI 3 模型评估结果
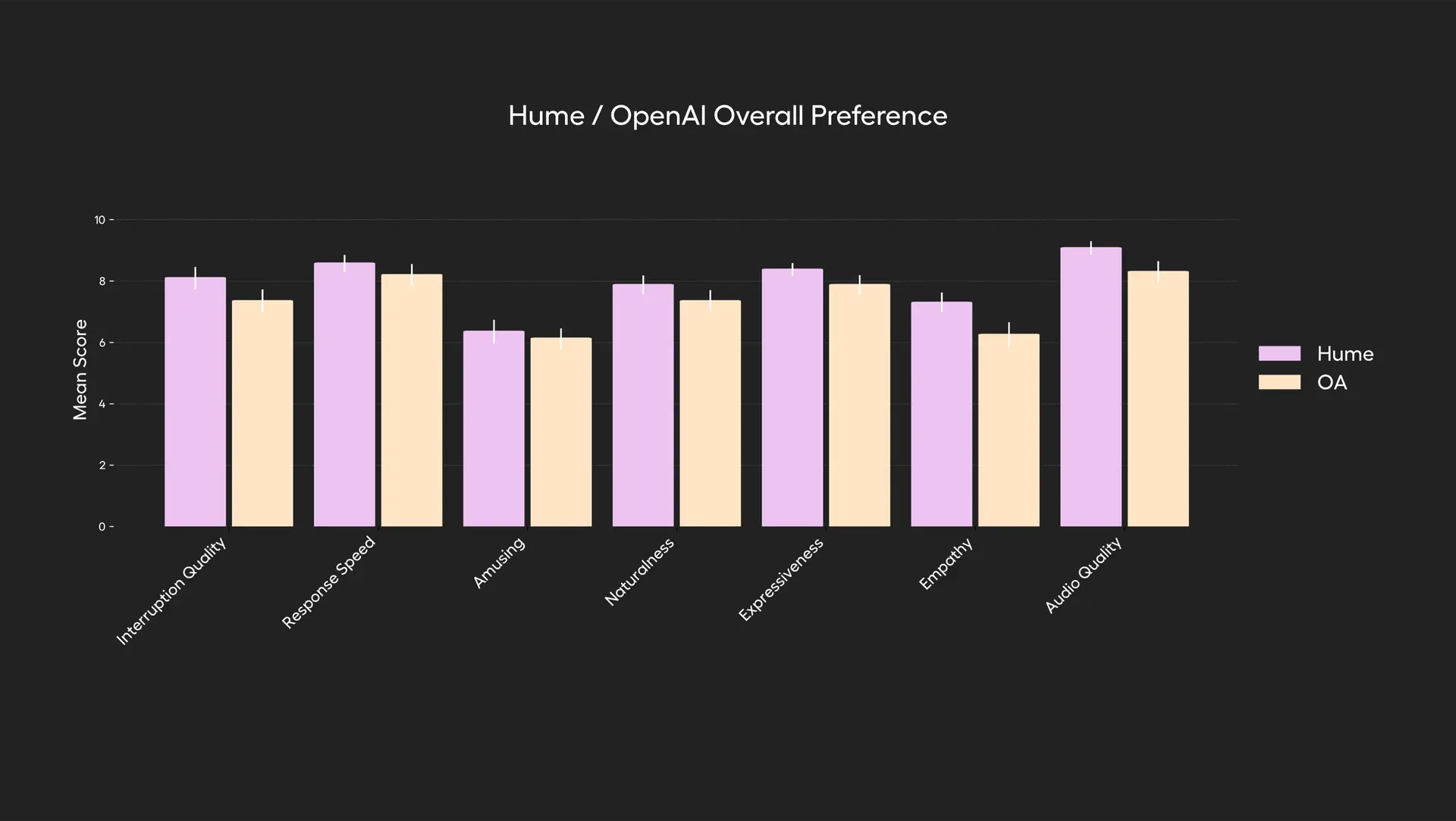
🧩 1. 整体对话体验评估(Overall Conversational Preference)
✔ 测试方法:
- 盲测方式:用户不知道使用的是哪个模型。
- 每个用户与模型进行 1–3 分钟的自由式对话,任务为“让 AI 说一些有趣的事情”。
- 用户从七个维度为模型打分。
📐 评估维度:
- Amusement(有趣程度)
- Audio quality(音频质量)
- Empathy(共情能力)
- Expressiveness(表达能力)
- Interruption handling(中断处理)
- Naturalness(自然度)
- Response speed(响应速度)
🏆 结果:
EVI 3 在所有七个维度上均优于 GPT-4o,综合偏好评分最高。
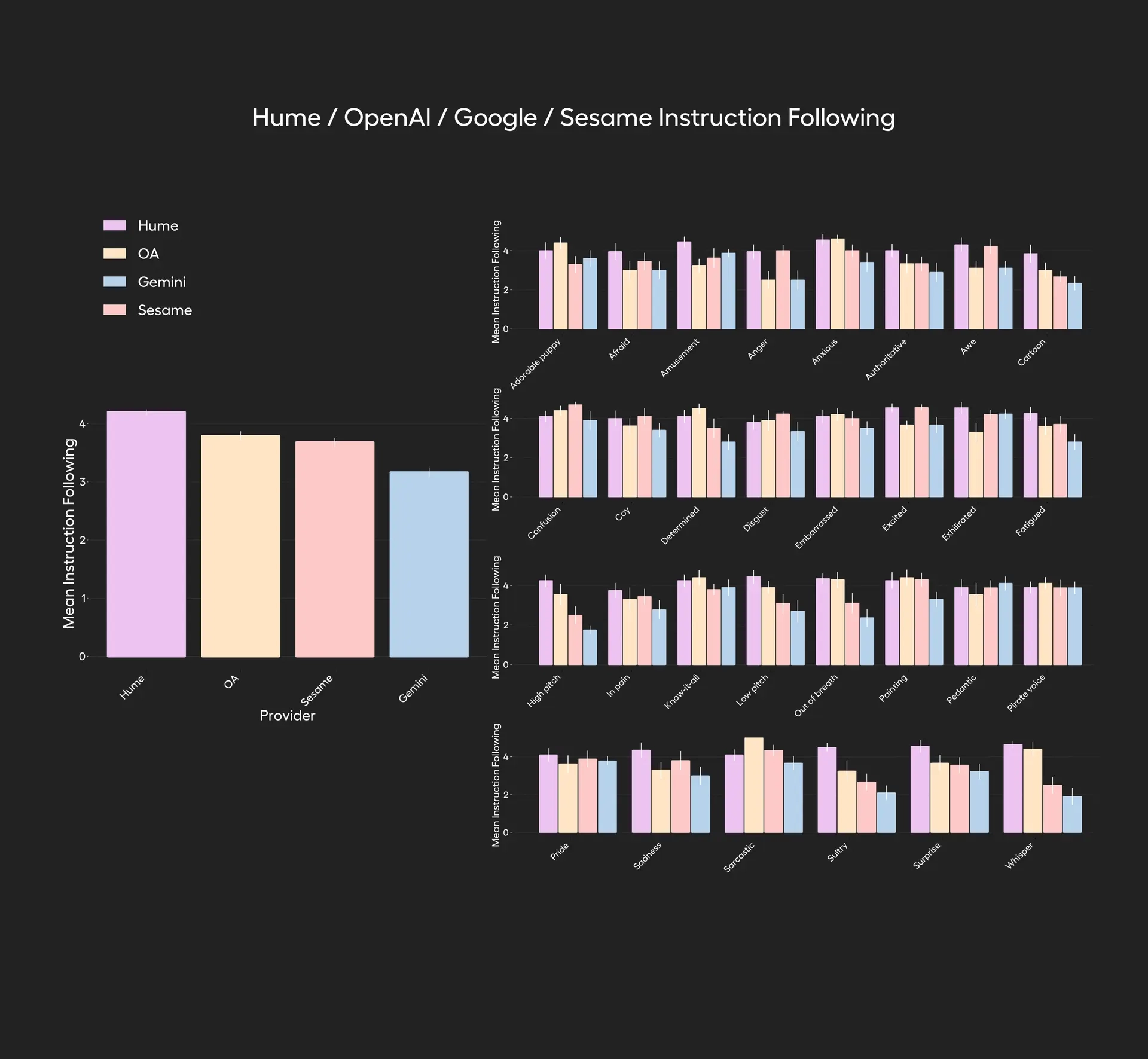
🎭 2. 情绪与风格表达能力评估(Emotion and Style Modulation)
✔ 测试方法:
- 参与者被要求让模型表达 30 种具体语气或风格(例如“生气”、“激动”、“演海盗”、“低声细语”等)。
- 对比对象:EVI 3、GPT-4o、Gemini、Sesame。
- 用户在每次对话后对模型表达该情绪/风格的准确度进行评分(1–5分)。
🧪 示例风格:
每位参与者都被要求让每个模型用以下列表中的一种特定情绪或风格说话:害怕、愤怒、焦虑、无聊、卡通、羞涩、沮丧、坚定、尴尬、兴奋、疲惫、高声调、惊恐、痛苦、像看到一只可爱的小狗、像万事通、像在欣赏一幅画、像在跑马拉松、低声调、单调、上气不接下气、迂腐、海盗、骄傲、悲伤、讽刺、闷热、耳语、大喊大叫…
🏆 结果:
EVI 3 平均得分显著高于 GPT-4o、Gemini 和 Sesame,表现出最强的语气/情绪变化表达能力。
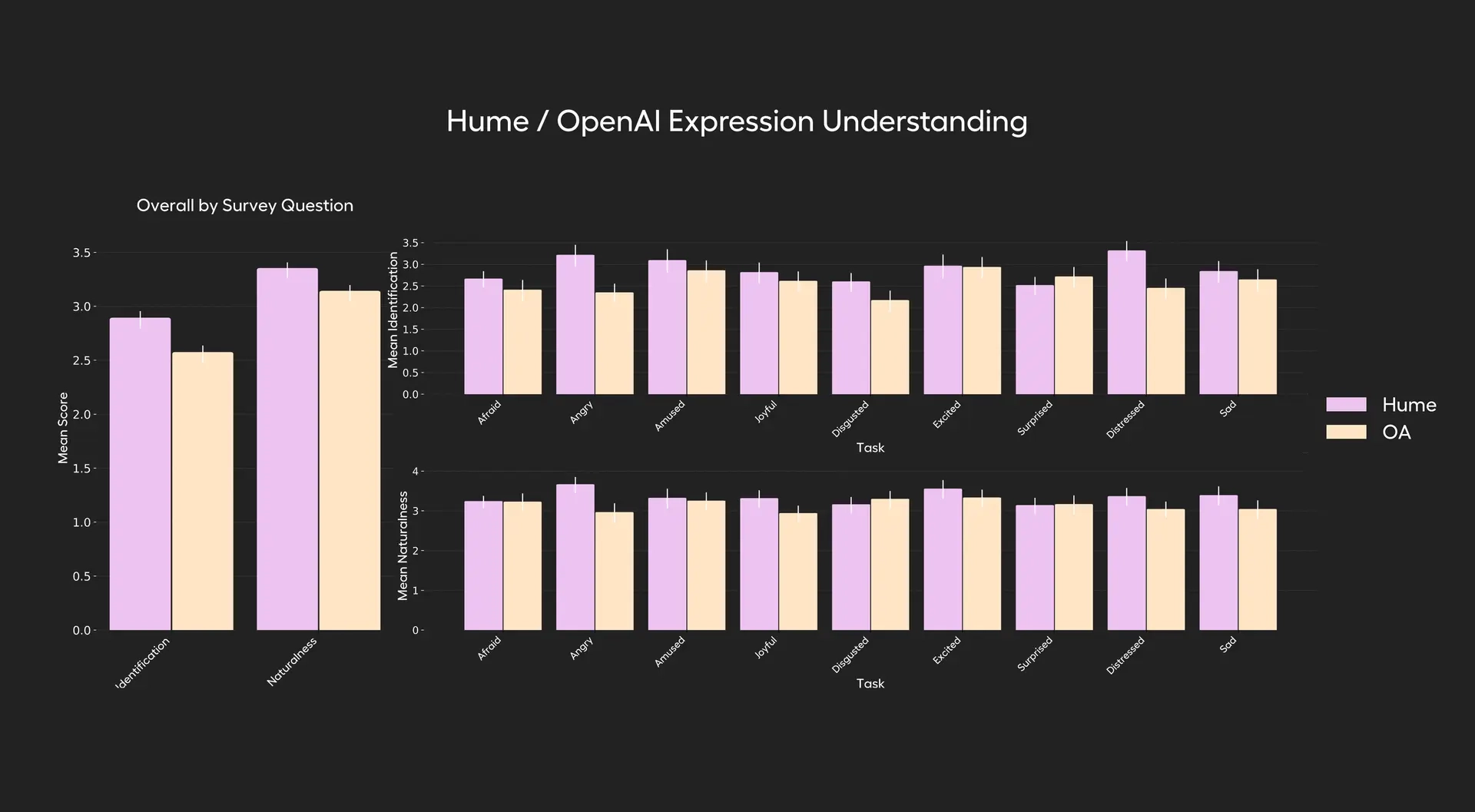
🎧 3. 情绪识别能力评估(Emotion Understanding)
✔ 测试方法:
- 所有用户说同一句话(如:“你能听出我语气里的情绪吗?”),但用不同情绪表达。
- 模型必须识别语音情绪,而非文字内容。
- 比较的是模型对以下 9 种情绪的识别能力。
🧪 情绪类型:
Afraid、Amused、Angry、Disgusted、Distressed、Excited、Joyful、Sad、Surprised
🎯 评分标准:
- 模型识别情绪的准确性(1–5分)
- 模型回应的自然度(1–5分)
🏆 结果:
EVI 3 在 9 种情绪中有 8 项识别准确率高于 GPT-4o,同时在回应自然度上也更优。
⏱️ 4. 实际响应延迟评估(Practical Latency Test)
✔ 测试方法:
测量用户说完话后,AI 开始发出回应之间的时间(对话延迟),在纽约测试,服务器在美西。

🏆 总结:
EVI 3 响应速度快,显著优于 GPT-4o,接近 Sesame,远快于 Gemini,适合实时语音对话场景。
官方介绍:https://www.hume.ai/blog/introducing-evi-3
在线体验:demo.hume.ai